Auswertung: EXMARaLDA Mini-Umfrage
Die EXMARaLDA Mini-Umfrage wurde am 10. September 2022 veröffentlicht. Sie ist immer noch offen, aber wir erwarten nicht mehr viele weitere Antworten und haben deshalb die Ergebnisse ausgewertet, die bis zum 10. Oktober eingegangen sind. Für Ungeduldige fasst das Video unten die Ergebnisse in musikalischer untermalter Form zusammen. Die sehr hilfreichen (und oft amüsanten) Kommentare der Teilnehmer — und unsere Kommentare zu einigen dieser Kommentare — haben wir in einem separaten Dokument zusammgestellt. [Ab hier ist alles auf Englisch, keine Zeit zum Übersetzen…]
Participants
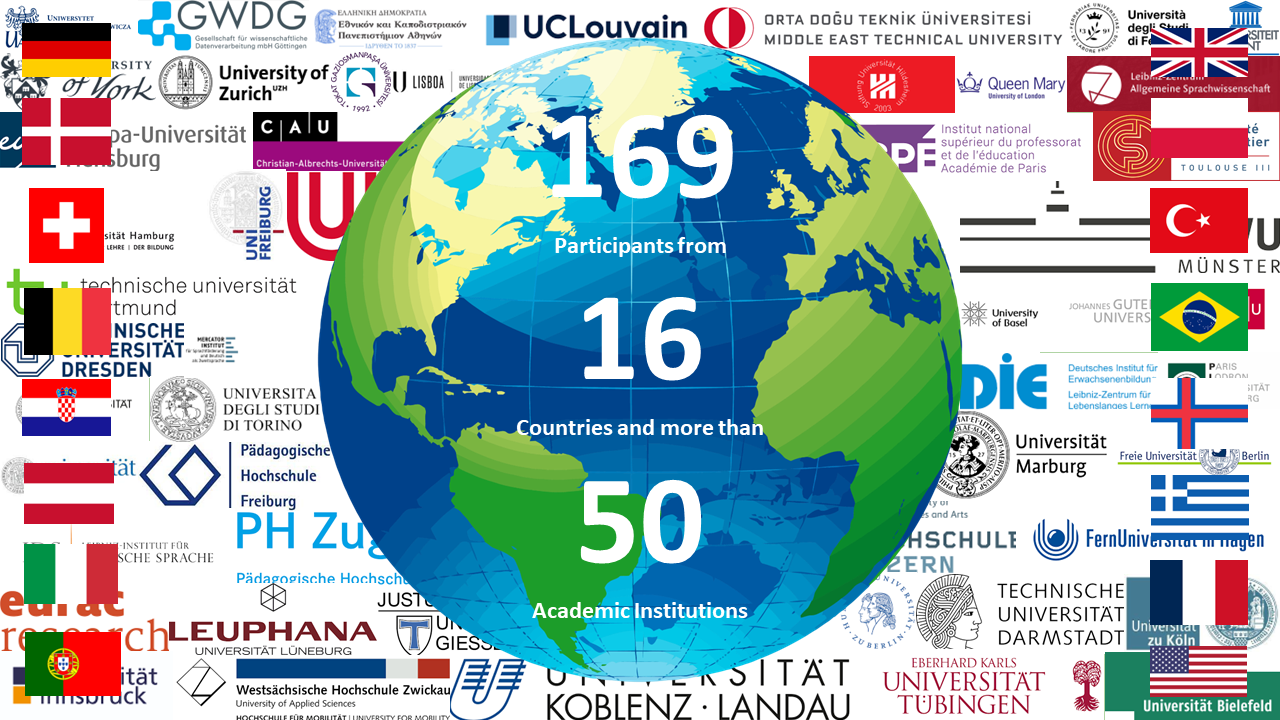
Calls for participation went out via the EXMARaLDA website, Twitter, Facebook and the usual suspects of mailing list. After four weeks, 169 participants had completely filled in the German (146) or the English (23) version of the survey. Those participants came from altogether 16 countries with Germany, Turkey and Switzerland being the most prominent. More than 50 academic institutions were named including many universities but also non-university research institutes. We are very happy with the response rate and would like to thank all those who participated very much!
1A. For what kind of language data are you using EXMARaLDA?
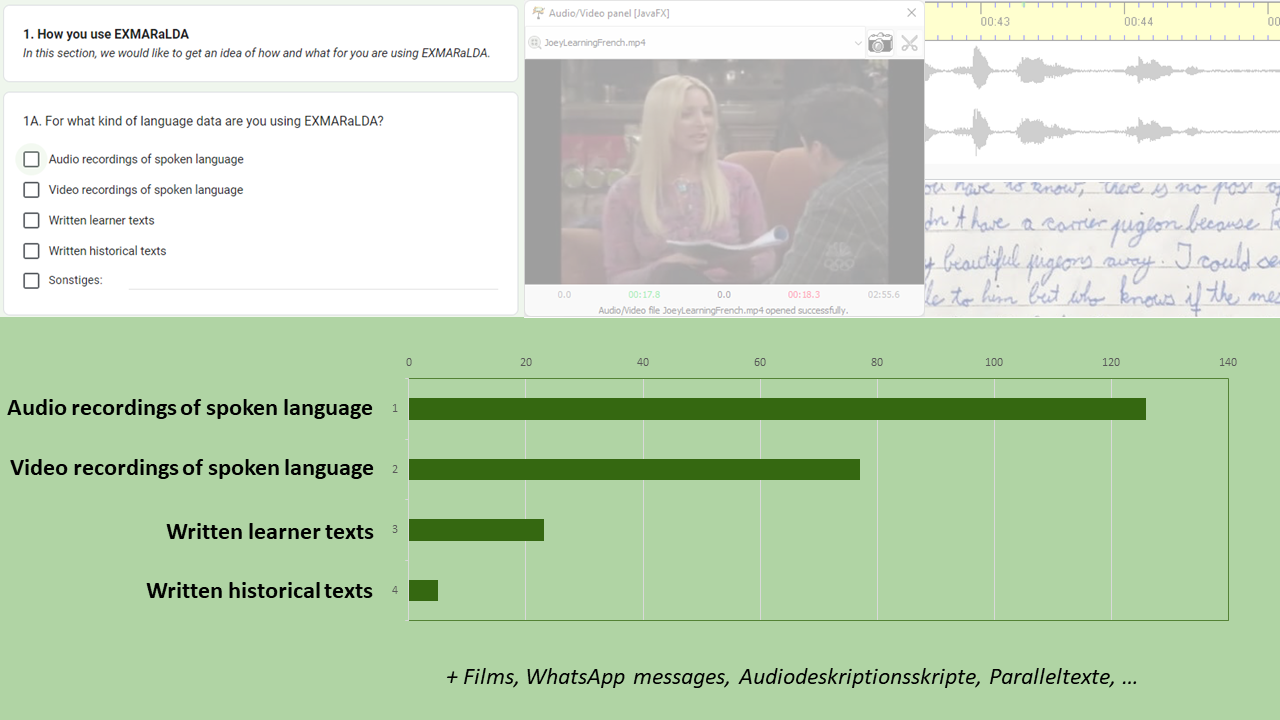
Not surprisingly, most respondents said they were using EXMARaLDA to transcribe or annotate audio recordings of spoken language. Video recordings are following not too far behind. Still, there is also a significant number of users using EXMARaLDA with written text — learner texts or historical texts. Other data types mentioned in the comments were films, WhatsApp messages, audio description scripts and parallel texts.
1B. For which language(s) are you using EXMARaLDA?
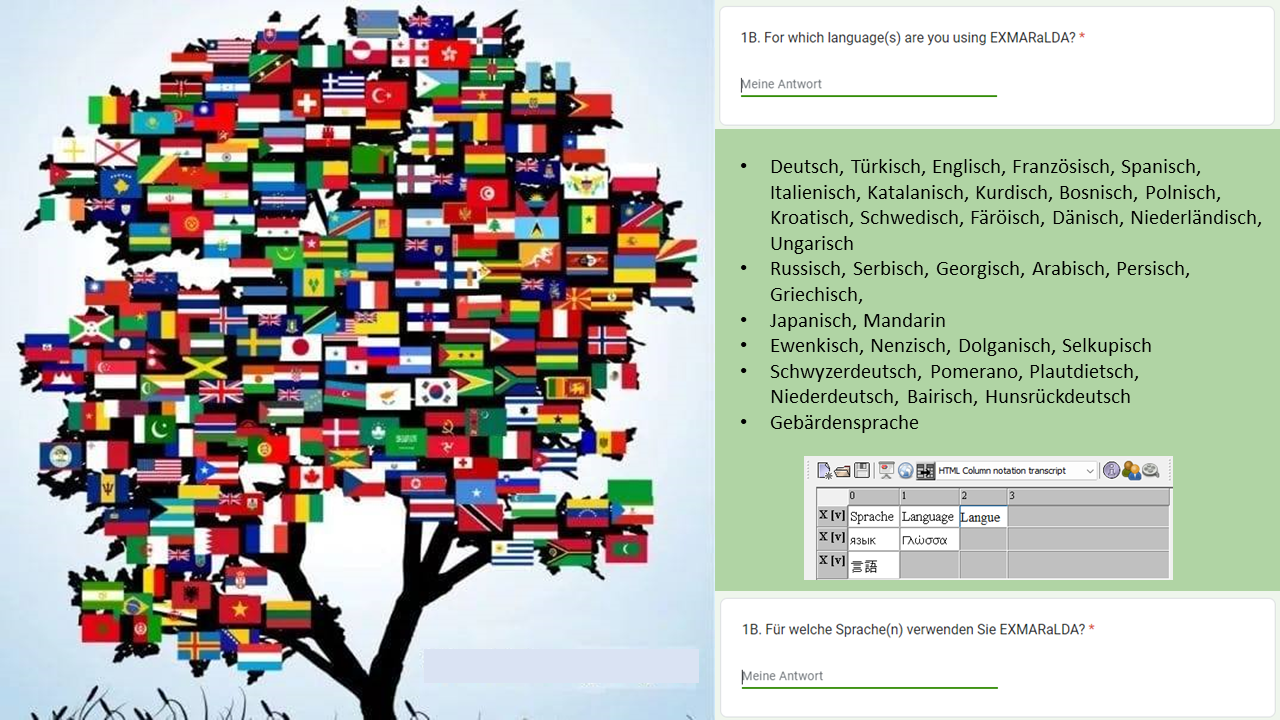
With its birthplace being the Special Research Centre on Multilingualism, we are especially proud of the broad spectrum of languages for which EXMARaLDA is used. Languages mentioned include the major European languages as well as Japanese and Manadarin Chinese. Exploiting EXMARaLDA’s Unicode capabilities, writing systems are not restricted to Latin alphabets, but also include Non-Latin alphabets and non-alphabetic writing systems. Minority and endangered languages as well as non-standard varieties also figure among the languages mentioned.
1C. With which EXMARaLDA tools do you work?
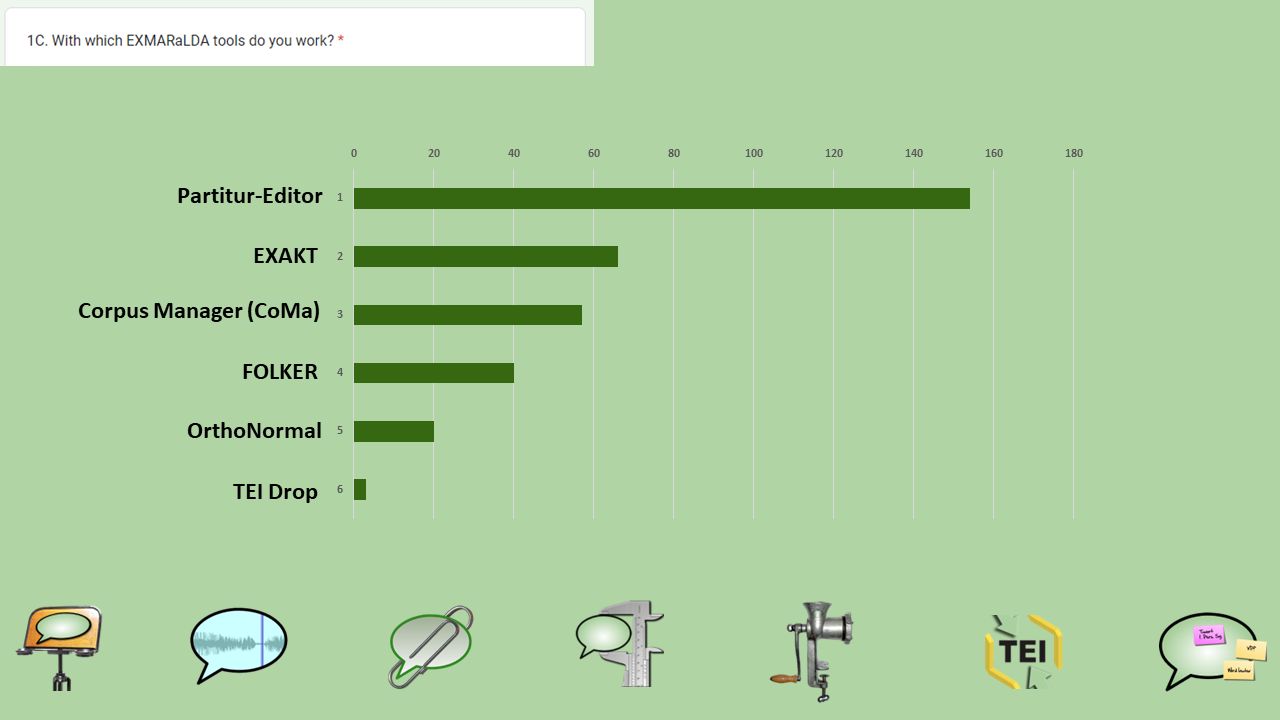
As expected, the Partitur-Editor is the most widely used of the EXMARaLDA tools. Still, a siginifant number of respondents also work (in that order) with EXAKT and the Corpus Manager (COMA). FOLKER and OrthoNormal, as later additions for the FOLK workflow, are also used by a non-negligible proportion of respondents.
1D. On which operating system are you mainly working with EXMARaLDA?
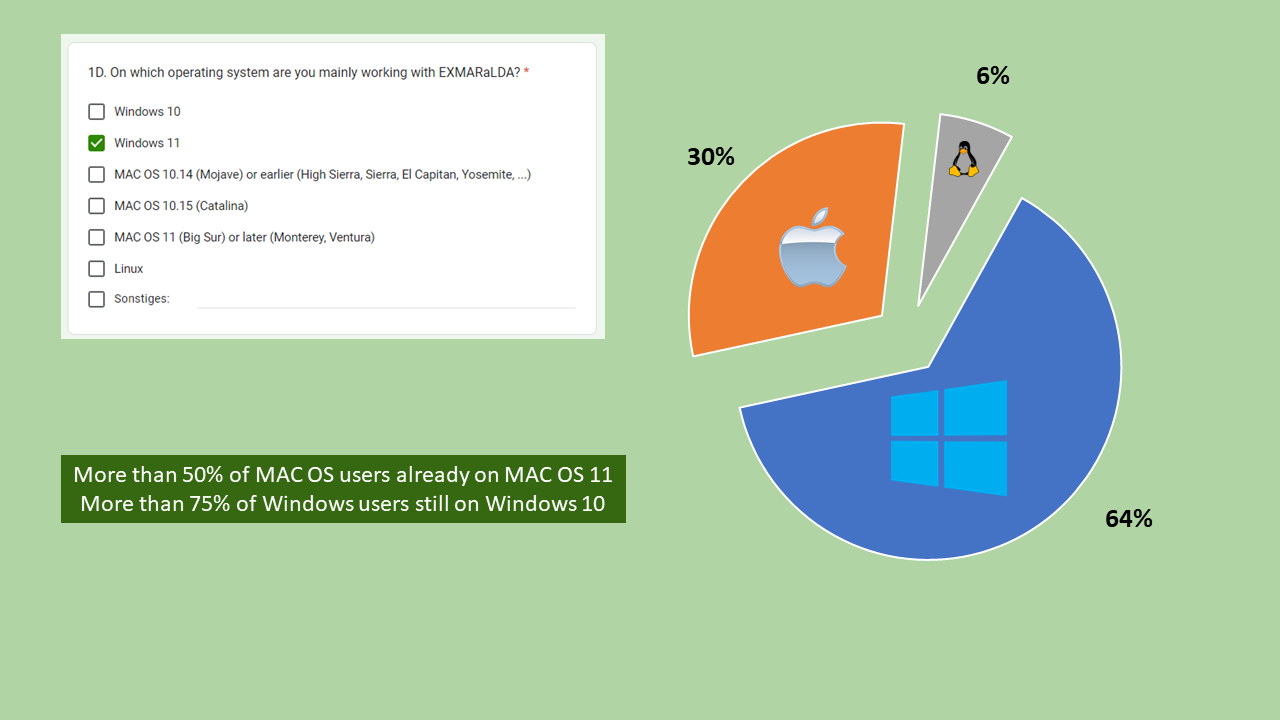
With 64%, Windows is clearly the most widely used operating system. MAC OS (which causes us some grief with its frequent non-downwards compatible updates) is the operating system of choice for 30% of respondents. With 6%, Linux is the least popular guy in the class.
It is worth mentioning that more than 50% of MAC OS users are already on MAC OS 11, i.e. the latest version of that OS, while only 25% of Windows users have already made the transition from Windows 10 to Windows 11.
1E. What other transcription, annotation or analysis tools are you using in your work beside EXMARaLDA?
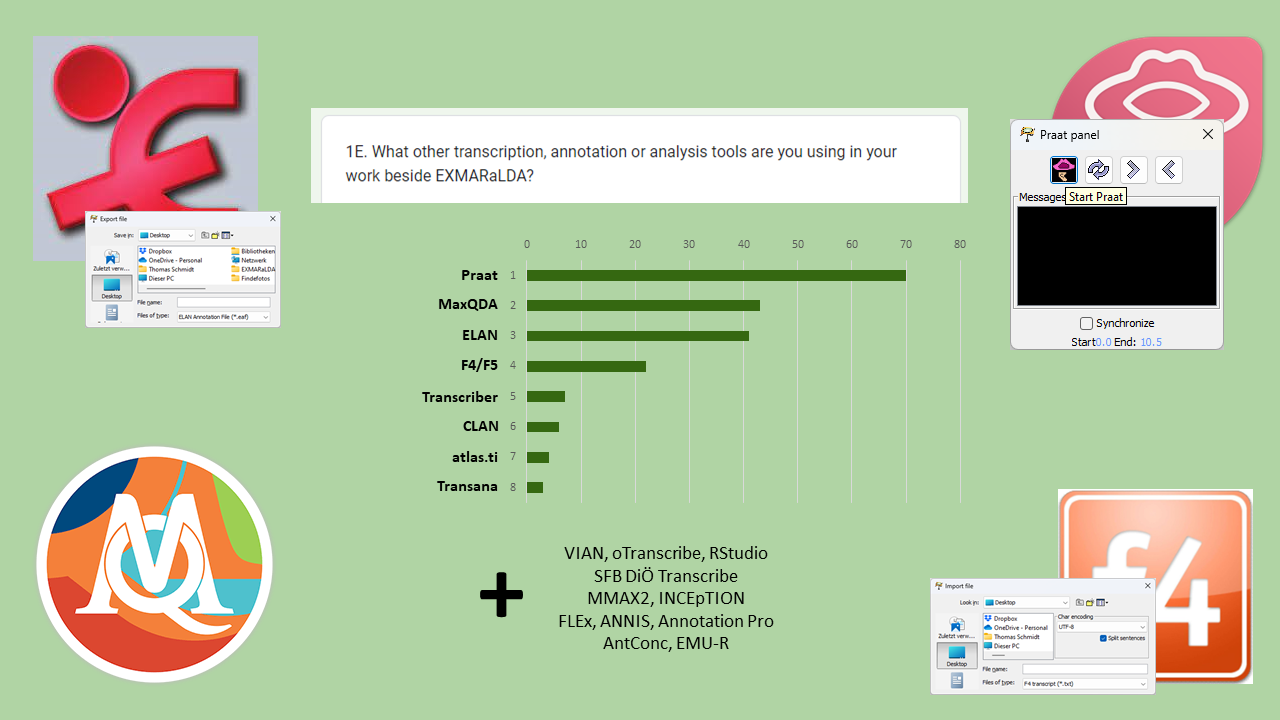
Praat is the most mentioned tool in this category with MaxQDA and ELAN following second and third. F4/F5 was also named by a non-negligible number of respondents. Other transcription tools (Transcriber, CLAN or Transana) or tools for qualitative analysis (atlas.ti) seem to be less widely used.
EXMARaLDA interoperates well with Praat and ELAN, and we know about the benefits of combining these tools in certain workflows. Interoperability with MaxQDA and F4/F5 is harder to establish, but we see their value as instruments of analysis and/or simple first transcription tools, so we will keep trying…
1F. and 1G. Do you use automatic speech recognition (ASR, SpeechToText) in your transcription workflows? Which automatic speech recognition services do you know or use?
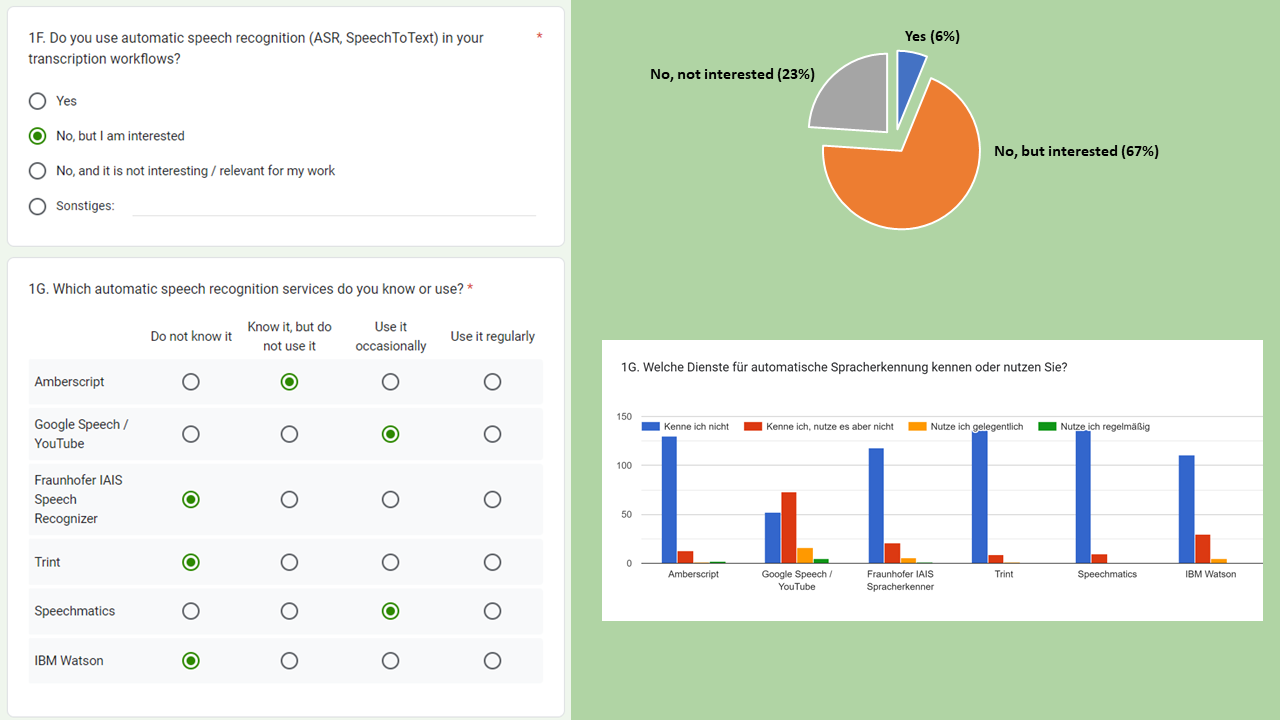
These questions were included to get an idea of how far the use of ASR technology, which has made considerable progress in the last two or three years, has spread among EXMARaLDA users. While only a small proportion of respondents (6%) say they are already working with such technology, a large proportion (67%) said they were interested in it.
YouTube/Google Speech API seems to be the platform most widely known in this area.
2A. In which disciplines are you working with EXMARaLDA (e.g. English linguistics, Oral History Studies)

If nothing else, the answers to these questions show how many different names there are for the disciplines in which EXMARaLDA is used. The word cloud on the left suggests that German linguistics, conversation analysis, German as a second/foreign language and corpus or computational linguistics are the most important disciplines in this respect.
2B. In what role are you working with EXMARaLDA?
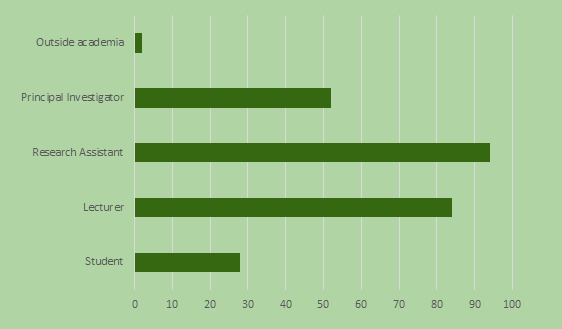
Research assistants and lecturers win this one. We suspect, however, that the results are somewhat biassed here. We know that EXMARaLDA is used a lot in teaching and also that most of the actual transcription work is done by student assistants (should have included that category 🙁 … ).
To remedy this, please feel free to ask your stundents or student assistants to complete the survey. It is still open: https://tinyurl.com/exmaralda-mini-survey
2C. Since when (approximately) have you been working with EXMARaLDA?
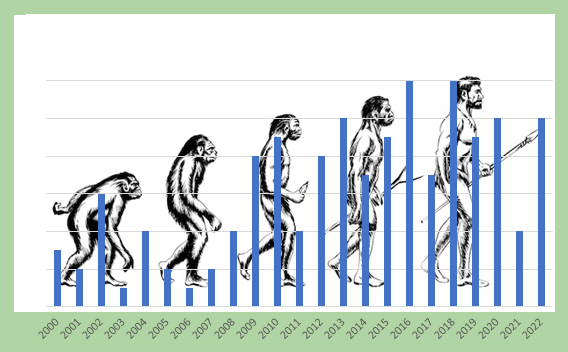
We were happy to say that some users have been true to EXMARaLDA since the beginning (with one participant even claiming to be using it since 1948!). Otherwise, results seem to suggest that new users are still coming in on a regular basis and that, for some reason we cannot fathom, 2016 must have been a particularly good year.
2D. How did you familiarize yourself with EXMARaLDA?
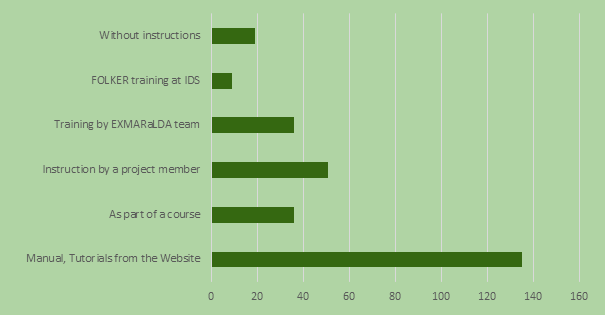
EXMARaLDA users do not seem to be RTFM users! By far the largest proportion say that they are at least in part self-taught using materials from the website. Thanks also to the project members who taught other project members and to the teachers instructing their students in seminars and other courses. „Professional“ training (by the EXMARaLDA or the FOLK team) was mentioned a lot in the comments as a service that could be expanded, and we will see what we can do. Congratulations to all those who managed to familiarize themselves with EXMARaLDA with no instructions at all!
Last but not least: Participants‘ comments

We are very, very (very, very!) grateful for the many comments participants provided in the free text fields. We learned a lot from them, got new ideas for improvement of the software (see GitHub issues derived from the comments), and had quite a few good laughs.
We have summarized (almost) all of the comments in this document, and added our own comments where we could think of any.