Training Corpus of Spoken Slovenian ROG 1.0
Anfang dieser Woche hat das Mezzanine-Projekt das Trainingskorpus des gesprochenen Slowenisch, ROG 1.0, veröffentlicht. Das Korpus ist über das CLARIN.SI-Repositorium verfügbar: https://www.clarin.si/repository/xmlui/handle/11356/1992.
ROG 1.0 ist die wichtigste Ressource für die slowenische Sprache, um Technologien zur Verarbeitung von Sprache oder Sprachtranskripten zu trainieren und zu evaluieren, wie z.B. Part-of-Speech-Tagger, Parser, Disfluency-Identifikatoren, Dialogakt-Klassifikatoren usw. Es eignet sich auch für die Bearbeitung von Forschungsfragen zur gesprochenen Sprache.
ROG 1.0 besteht aus zwei Teilen:
ROG-SST besteht aus ausgewählten Gos 2.1-Transkriptionen (http://hdl.handle.net/11356/1863) mit:
- manuell zugewiesenen Lemmata und morphosyntaktischen Tags nach dem MULTEXT-East Annotationsschema (https://nl.ijs.si/ME/V6/msd/html/msd-sl.html),
- manuellen Annotationen nach dem Annotationsschema Universal Dependencies (d.h. Part-of-Speech-Kategorien, morphologische Merkmale und syntaktische Dependenzstrukturen)
Insgesamt umfasst ROG-SST 76.341 Wörter und 6.108 Sätze.
ROG-Art besteht aus:
- allen Annotationsschichten aus ROG-SST
- Annotationen zu prosodischen Einheiten
- Annotation von Disfluenzen
- Annotation von Dialoghandlungen
ROG-Art umfasst 39.001 Wörter und 1.969 Sätze.
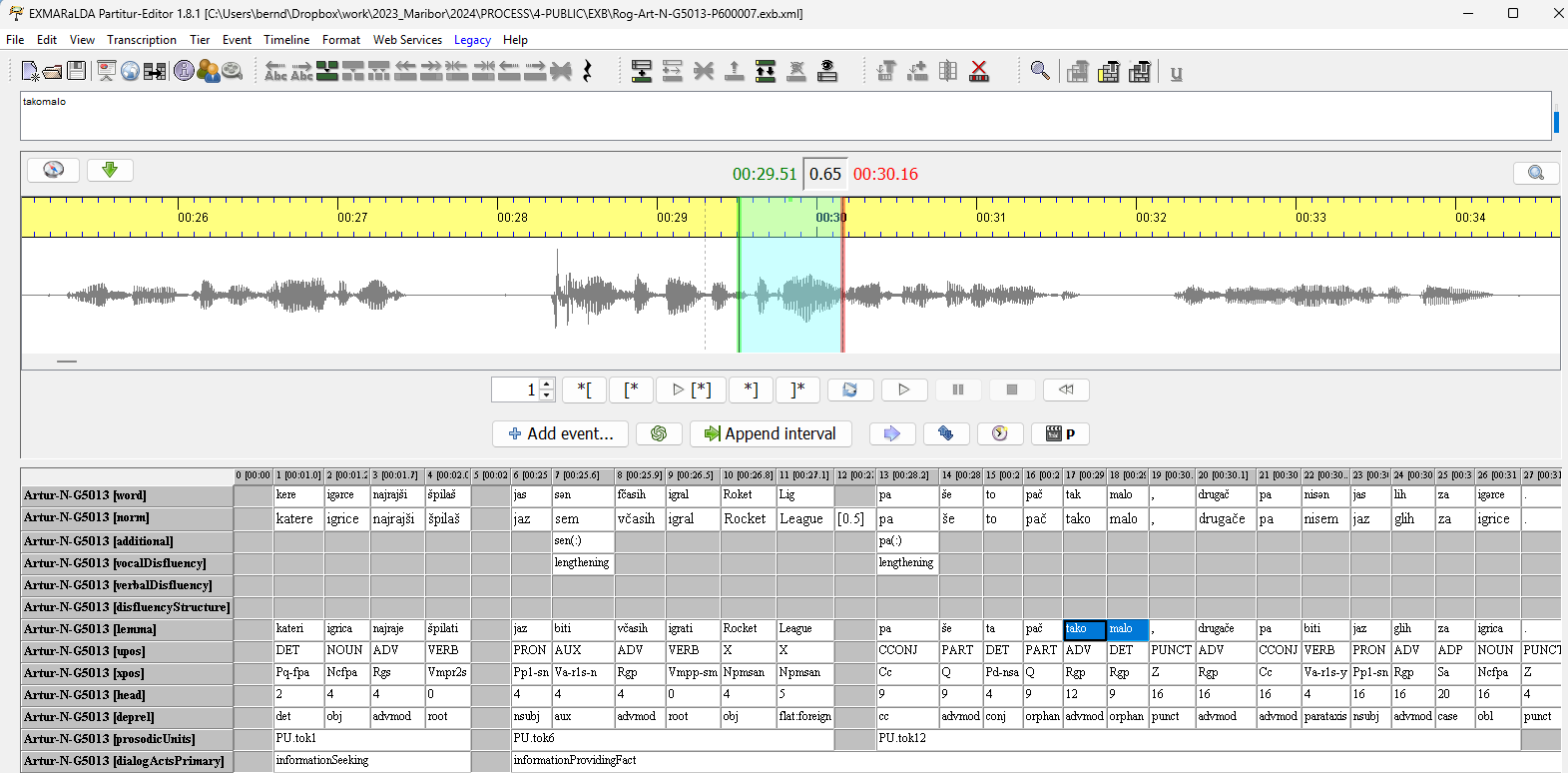
ROG-Art wurde mit dem EXMARaLDA Partitur-Editor annotiert und kann als EXMARaLDA-Korpus heruntergeladen werden:
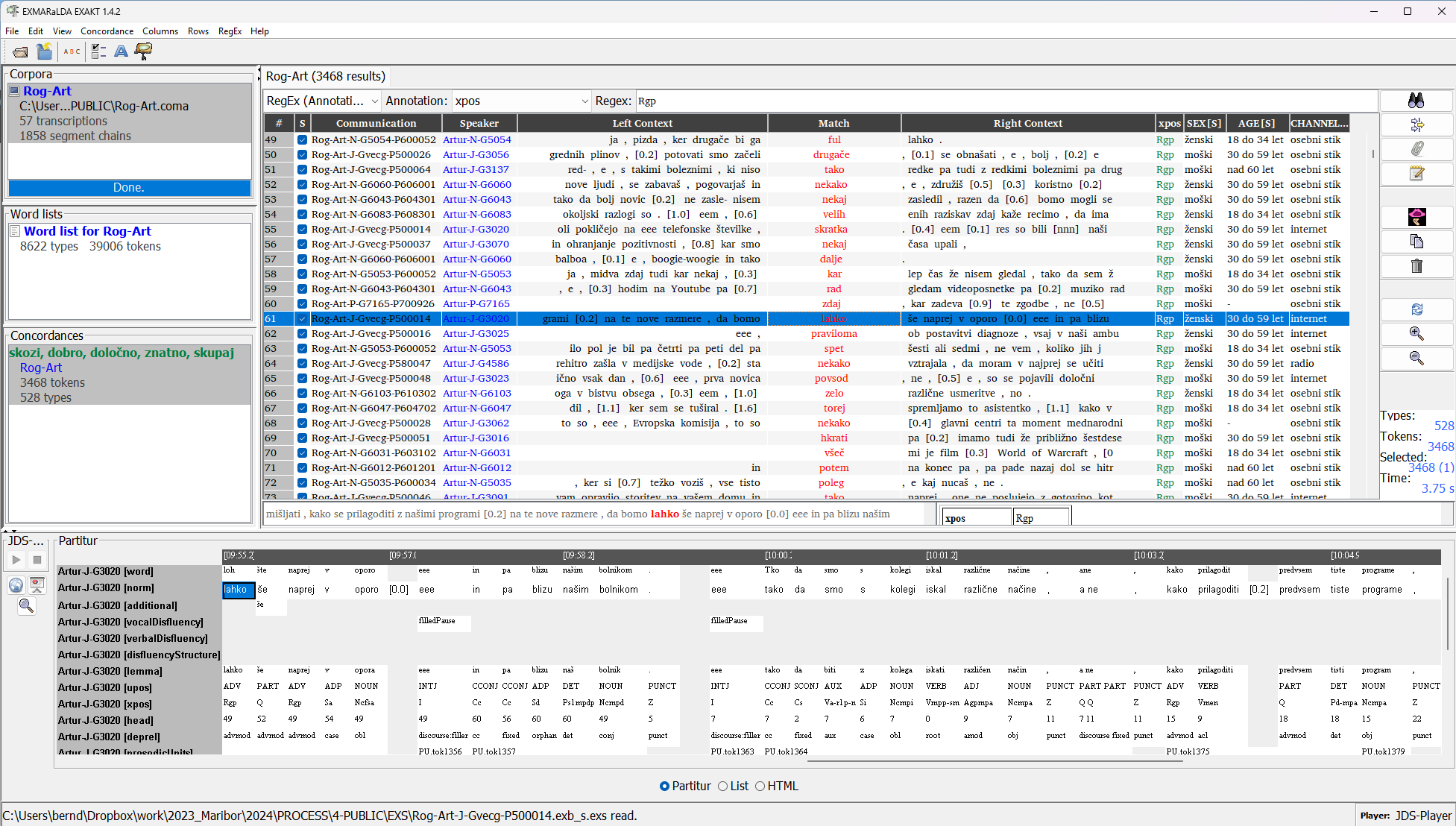
Alle Annotationsspuren und verschiedene Metadaten zu SprecherInnen und Kommunikationen können mit EXAKT durchsucht und analysiert werden: