
EXMARaLDA-gestützte Korpora bedrohter Sprachen Sibiriens: Das INEL-Projekt
Von Elena Lazarenko und Alexandre Arkhipov
Eine Sammlung von Korpora, die mehrere stark bedrohte Sprachen Nordeurasien umfasst, wird vom Akademien-Langzeitprojekt INEL (2016–2033) am Zentrum für nachhaltiges Forschungsdatenmanagement der Universität Hamburg gehostet. Unsere neuesten Veröffentlichungen (2024–2025) umfassen die uralischen Sprachen Enets, Nenets und Nganasan aus dem hohen Norden sowie Tavda-Mansi, und die tungusische Sprache Evenki.
Die Korpora können unter der Lizenz CC BY-NC-SA 4.0 heruntergeladen und offline genutzt werden sowie über eine webbasierte Suchoberfläche abgerufen werden.
Das Projekt wird von der Akademie der Wissenschaften in Hamburg im Rahmen des gemeinsam von Bund und Ländern finanzierten Akademieprogramms gefördert.
Forschungsziele
Seit 2016 liefert das Akademien-Langzeitprojekt INEL („Grammatiken, Korpora und Sprachtechnologie für indigene nordeurasische Sprachen“) tief annotierte Korpora und begleitende linguistische Ressourcen für ausgewählte stark bedrohte Sprachen und Varietäten.
Die Gebiete, auf die sich die Projektforschung konzentriert, sind die Heimat vieler indigener Sprachen. Die meisten davon sind stark vom Aussterben bedroht, einige werden nur noch von wenigen Dutzend Menschen gesprochen, andere sind bereits vollständig ausgestorben. Das INEL-Projekt hat sich zum Ziel gesetzt, deren Materialien zu sammeln, zu digitalisieren, linguistisch zu annotieren und in Form von Sprachkorpora dauerhaft verfügbar zu machen.
Im Gegensatz zu vielen aktuellen Sprachdokumentationsprojekten wurden die meisten unserer Daten bereits früher gesammelt – einige davon in den letzten ein oder zwei Jahrzehnten, andere sind mehr als ein Jahrhundert alt. Eine der Herausforderungen besteht darin, die Daten unterschiedlicher Epochen und Herkunft in ein einheitliches digitales Format zu bringen, das eine konsistente linguistische Analyse ermöglicht.
Methoden
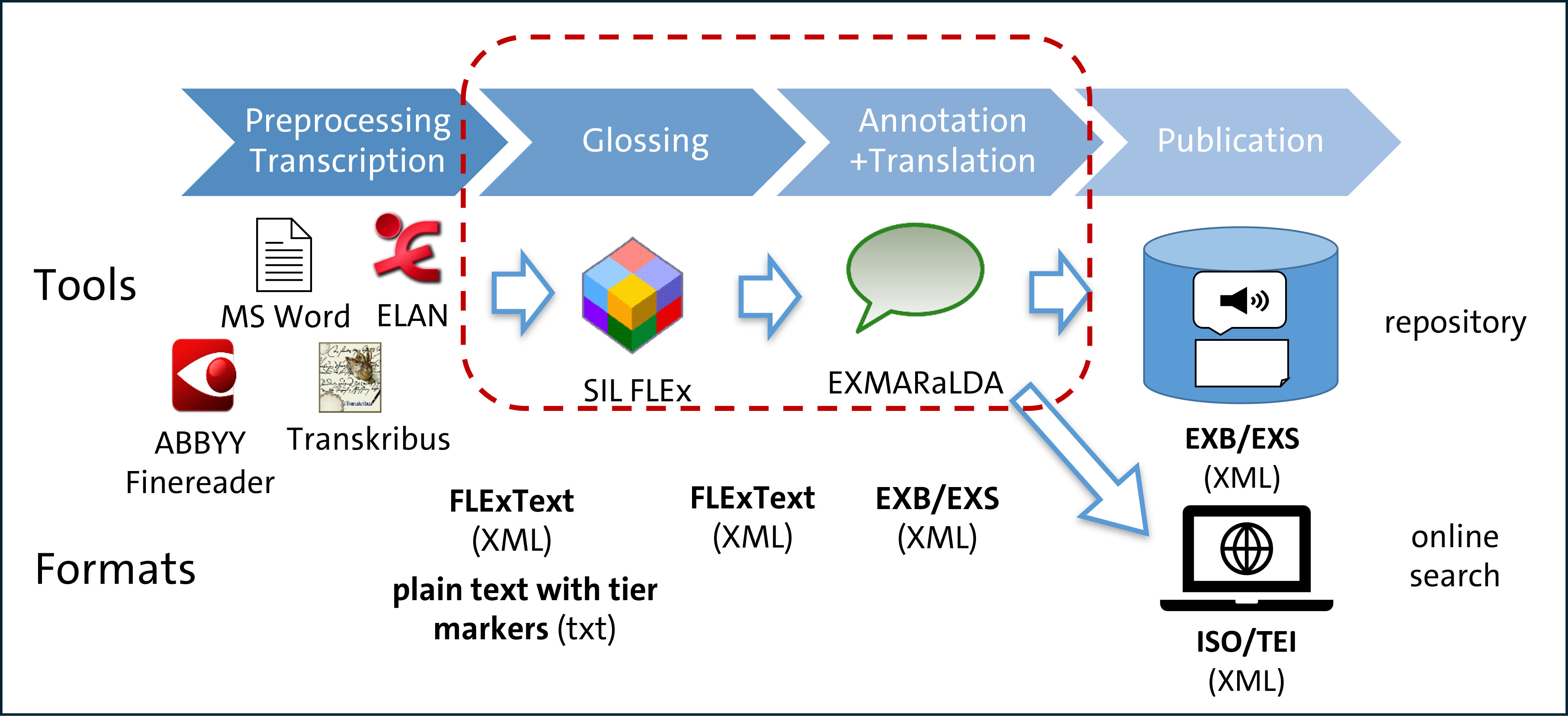
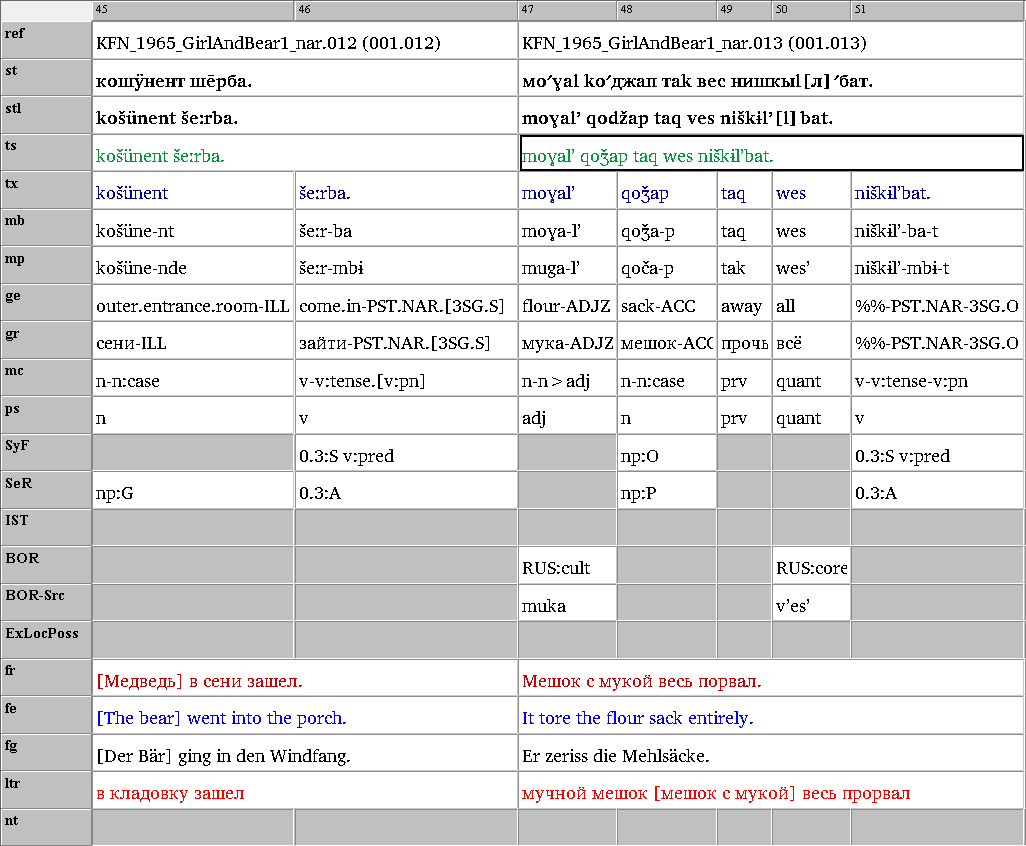
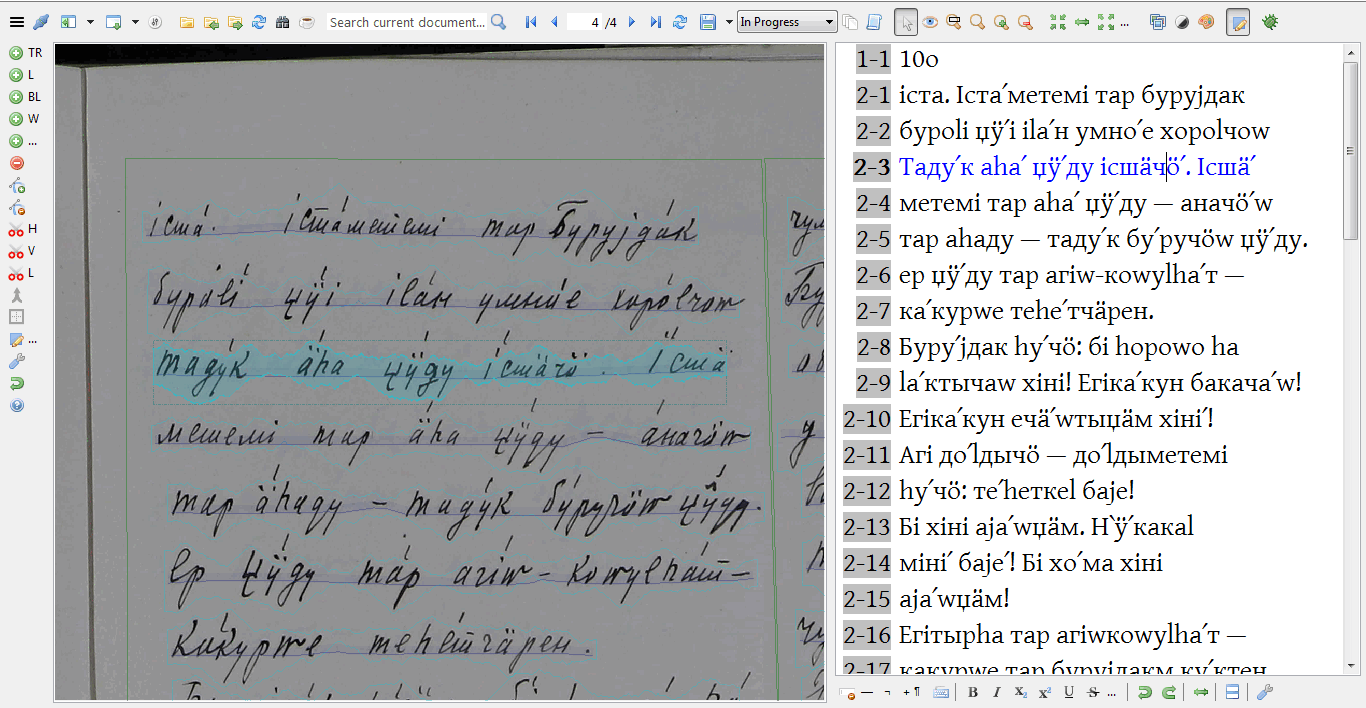
Wir arbeiten mit verschiedenen Formaten von Originaldaten (Primärdaten), wie Büchern, Tonaufnahmen und Manuskripten. Sie alle erfordern individuell angepasste Vorverarbeitungsworkflows, um in XML-Transkripte umgewandelt zu werden, die dann in SIL FLEx einer grammatikalischen Analyse unterzogen werden. In dieser Phase wird jede Wortform morphologisch analysiert, um einen interlinearen glossierten Text (IGT) zu erhalten, der eine Standarddarstellung in der Sprachtypologie und verwandten Disziplinen ist.
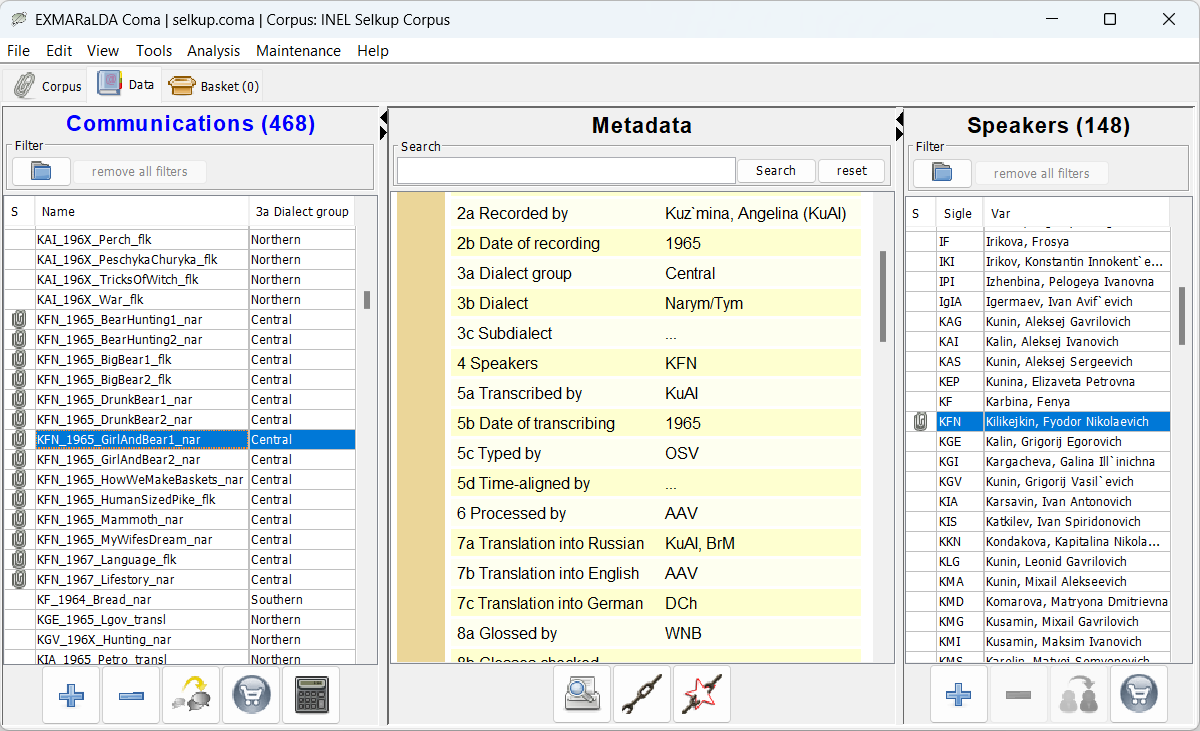
Im nächsten Schritt wird das Korpus mit dem EXMARaLDA-Paket erstellt: Wir erstellen die Hauptmetadatendatei, exportieren die Transkripte im EXMARaLDA-Basistranskriptionsformat und verknüpfen sie miteinander.
Die Coma-Datei enthält umfangreiche Informationen darüber, wann und wo die Daten aufgezeichnet wurden, wer an der Datenerfassung, Annotation und Kuratierung beteiligt war, sowie biografische und soziolinguistische Informationen über die Sprecher, sofern verfügbar.
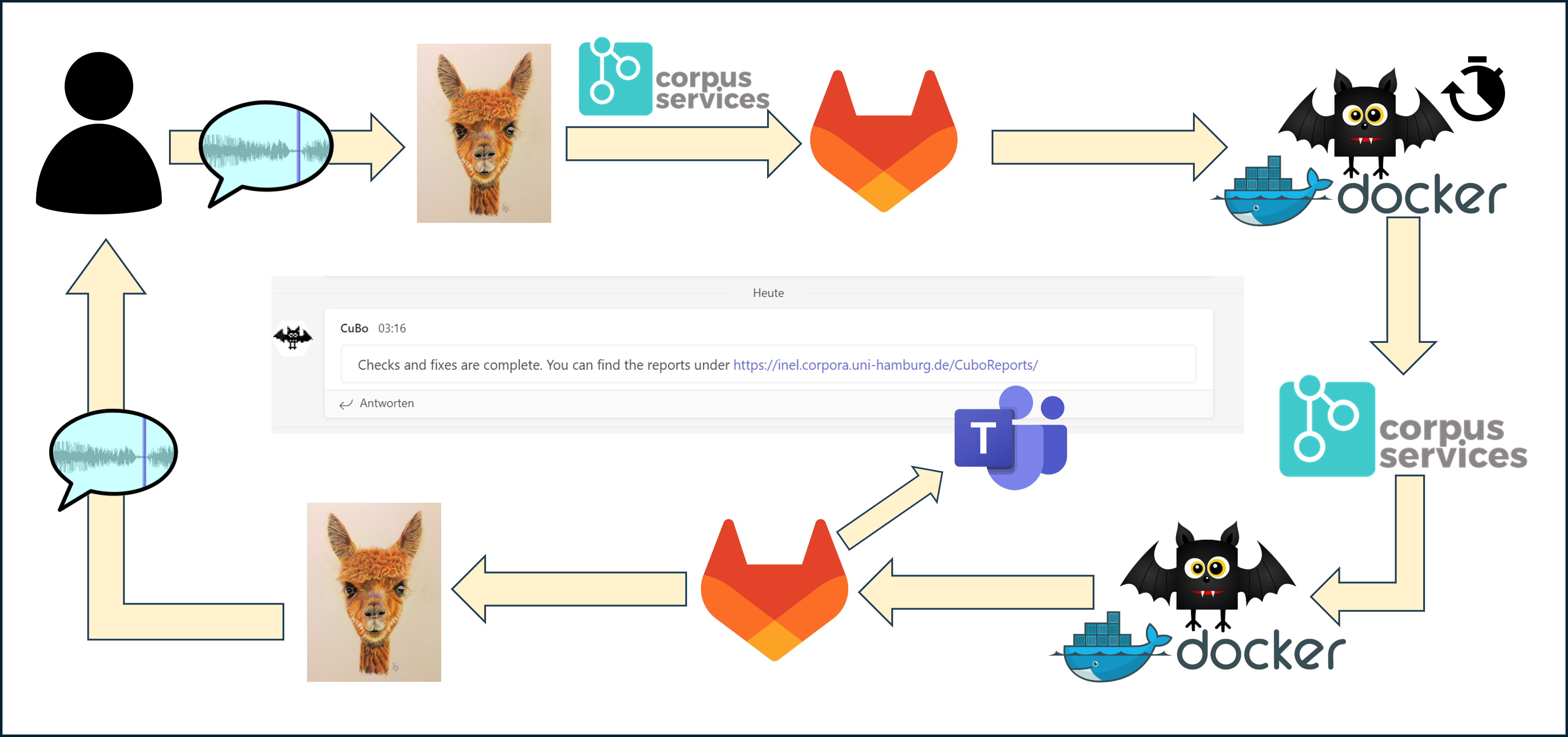
Nach der Übertragung in die EXMARaLDA-Formate werden die Daten weiter annotiert und umfassend kuratiert, sowohl manuell durch die Projektmitglieder als auch automatisch. Dies umfasst automatische Überprüfungen und Korrekturen mithilfe des projektspezifischen Corpus Services-Frameworks, das den EXMARaLDA-Code nutzt (Hedeland/Ferger 2020, Riaposov/Lazarenko 2024).
Mithilfe des EXMARaLDA Partitur-Editors fügen wir weitere Analyseebenen hinzu , einschließlich der Annotation syntaktischer Funktionen und semantischer Rollen, Entlehnungen und Code-Switching (Arkhipov 2020). Alle Texte werden ins Englische und Russische übersetzt, die meisten zusätzlich ins Deutsche. Die Original-Transkriptionen und Übersetzungen aus den vorhandenen Publikationen sind ebenfalls enthalten. Insgesamt kommen wir auf mehr als 20 Annotationsspuren pro Sprecher. Außerdem wird die Eventstruktur durch die Segmentierung in Wörter und Sätze bestimmt, von denen nur die Sätze zeitlich aligniert sind. Diese komplexe Struktur erforderte spezielle Anpassungen in EXMARaLDA, darunter z. B. die Möglichkeit, mehrere Annotationszellen zusammen zu kopieren und einzufügen (z. B. einen Satz mit allen seinen Wörtern und Annotationsspuren).
Ein neuer eventbasierter Segmentierungsalgorithmus, der speziell für das INEL-Projekt entwickelt wurde, ermöglicht einen reibungslosen und fehlerfreien Export in das ISO/TEI-Format, das mit den Korpora bereitgestellt wird und insbesondere von der Online-Suchplattform Tsakorpus verwendet wird.
Jedes Korpus wird als herunterladbares Archiv veröffentlicht, das alle Dateien enthält, die für die Offline-Bearbeitung der Daten mit den EXMARaLDA-Tools erforderlich sind, darunter die Hauptmetadatendatei, Basis- und segmentierte Transkriptionen, weitere Exportformate (ISO/TEI und ELAN und optional die Quelldaten in Form von Audioaufnahmen und/oder PDF-Scans.
Referenzen
- Arkhipov, A. 2020. INEL Corpora General Transcription and Annotation Principles. Working Papers in Corpus Linguistics and Digital Technologies: Analyses and Methodology. Vol. 5. Szeged; Hamburg. https://doi.org/10.14232/wpcl.2020.3
- Hedeland, H. & Ferger, A. 2020. Towards Continuous Quality Control for Spoken Language Corpora. International Journal for Digital Curation, 15(1). https://doi.org/10.2218/ijdc.v15i1.601
- Riaposov, A. and E. Lazarenko. 2024. Corpus Services: A Framework to Curate XML Corpus Data. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC—COLING 2024), pages 4030–4035, Torino, Italia. ELRA and ICCL. https://aclanthology.org/2024.lrec-main.358/
Teilprojekte und Korpora
Dolganisch
Däbritz, Chris Lasse; Kudryakova, Nina; Stapert, Eugénie. 2022. INEL Dolgan Corpus. Version 2.0. Publication date 2022-11-30. https://hdl.handle.net/11022/0000-0007-F9A7-4.
Online-Suche: https://inel.corpora.uni-hamburg.de/DolganCorpus/search
Dolgan gehört zur nord-sibirischen Gruppe der nordöstlichen Turksprachen und wird von etwa 1000 Menschen auf der Taimyr-Halbinsel und in benachbarten Gebieten im hohen Norden Sibiriens gesprochen. Die Daten im INEL Dolgan Corpus 2.0 stammen aus veröffentlichten Texten sowie aus Feldforschungsaufnahmen und Aufnahmen, die vom Taymyr House of Folk Art zur Verfügung gestellt wurden.
- Glossierter (durchsuchbarer) Teil: 136 Texte, 14.193 Sätze, 97.625 Token
Gesamtdauer der Audioaufnahmen: 14 Std. 15 Min. - Archivteil: 37 Audioaufnahmen
Gesamtdauer der Audioaufnahmen: 10 Std. 00 Min.
Enzisch
Shluinsky, Andrey; Khanina, Olesya; Wagner-Nagy, Beáta. 2024. INEL Enets Corpus. Version 1.0. Publication date 2024-11-30. https://hdl.handle.net/11022/0000-0007-FE1D-C.
Online search: https://inel.corpora.uni-hamburg.de/EnetsCorpus/search
Das INEL Enets Corpus 1.0 umfasst Texte, die zwischen 1962 und 2017 in Tundra- und Waldenzisch (< Samojedisch < Uralisch) aufgezeichnet wurden. Die Daten stammen aus verschiedenen veröffentlichten und archivierten Audioaufnahmen sowie aus veröffentlichten Texten und archivierten Manuskripten. Soweit verfügbar, sind auch Videoaufnahmen in das Korpus aufgenommen worden.
- Waldenzisch: 541 texts, 41,396 Sätze, 173,379 tokens
- Tundraenzisch: 137 Texte, 12,737 Sätze, 45,331 Token
- Gesamt: 678 Texte, 54,133 Sätze, 218,710 Token
- Gesamtdauer der Audioaufnahmen: 43 Std. 26 Min.

Ewenkisch
Däbritz, Chris Lasse; Gusev, Valentin; Stoynova, Natalia. 2024. INEL Evenki Corpus. Version 2.0. Publication date 2024-12-31. Archived at Universität Hamburg. https://hdl.handle.net/11022/0000-0007-FE38-D.
Online search: https://inel.corpora.uni-hamburg.de/EvenkiCorpus/search
Ewenkisch ist eine tungusische Sprache, deren Sprecher über Sibirien und den Fernen Osten verstreut sind. Das INEL Evenki Corpus 2.0 umfasst nördliche (Taimyr, Khantayskoe Ozero, Ilimpi, Yerbogachyon) und südliche (Sym, Barhahan und in geringerem Umfang Steintunguska und Nepa) Ewenki-Dialekte. Dies sind die Dialekte, die mit anderen Sprachen des INEL-Projekts in Kontakt stehen oder standen, vor allem Dolganisch und Selkupisch. Das Korpus enthält Texte aus verschiedenen Quellen, die bis in die 1900er/1910er Jahre zurückreichen.
- 612 Texte, 19,931 Sätze, 93,264 Token
- Gesamtdauer der Audioaufnahmen: 3 Std. 58 Min. (69 Texte)
Kamassisch
Gusev, Valentin; Klooster, Tiina; Wagner-Nagy, Beáta. 2023. “INEL Kamas Corpus.” Version 2.0. Publication date 2023-12-31. http://hdl.handle.net/11022/0000-0007-FC25-4.
Online search: https://inel.corpora.uni-hamburg.de/KamasCorpus/search
Kamas ist eine ausgestorbene samojedische Sprache (< Uralisch) aus Südsibirien. Das INEL Kamas Corpus 2.0 besteht aus zwei Teilen: Folkloretexten, gesammelt von Kai Donner zwischen 1912 und 1914, und transkribierten Audioaufnahmen der letzten Sprecherin von Kamas, Klavdiya Plotnikova, die zwischen 1964 und 1970 entstanden sind.
- Gesamt: 154 Texte, 13,876 Sätze, 63,810 Token
- Gesamtdauer der Audioaufnahmen: ca. 14 Std.
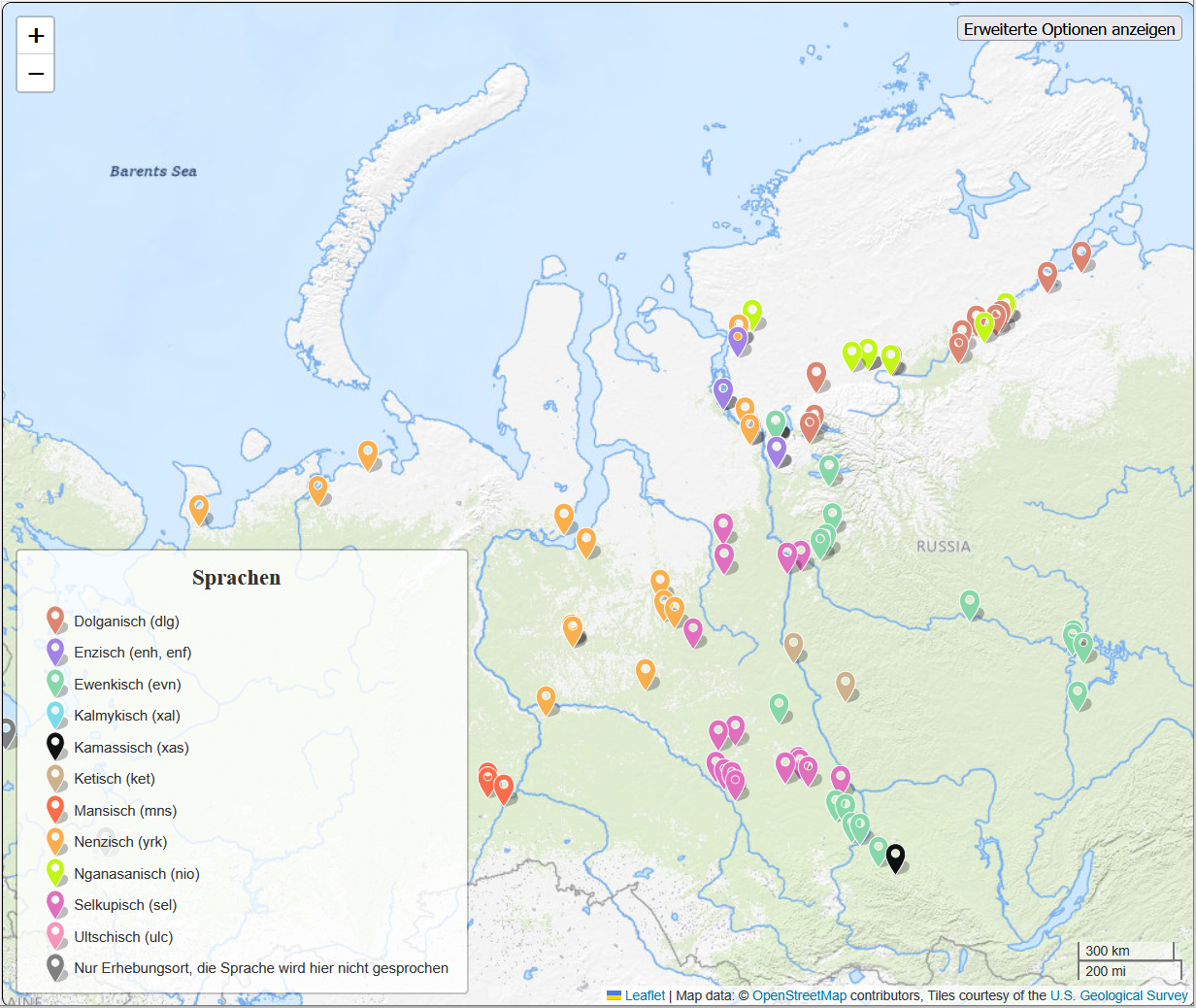
Nenets
Budzisch, Josefina; Wagner-Nagy, Beáta. 2024. INEL Nenets Corpus. Version 1.0. Publication date 2024-12-31. https://hdl.handle.net/11022/0000-0007-FE37-E.
Online search: https://inel.corpora.uni-hamburg.de/NenetsCorpus/search
Das INEL Nenets Corpus 1.0 umfasst Texte, die zwischen 1940 und 2011 in beiden nenzischen Varietäten – Waldnenzisch und Tundranenzisch (< Samojedisch < Uralisch) – aufgezeichnet wurden. Die meisten Texte in diesem Korpus stammen aus veröffentlichten Werken. Für einen Text liegt auch eine Audioaufnahme vor.
- Waldnenzisch: 80 Texte, 3,709 Sätze, 23,597 Token
- Tundranenzisch: 56 Texte, 6,545 Sätze, 37,681 Token
- Gesamt: 136 Texte, 10,254 Sätze, 61,278 Token
- Gesamtdauer der Audioaufnahmen: 45 Min.
Nganasanisch
Brykina, Maria; Gusev, Valentin; Szeverényi, Sándor; Wagner-Nagy, Beáta. INEL Nganasan Corpus. Version 1.0. Publication date 2025-05-02. https://hdl.handle.net/11022/0000-0007-FE63-C.
Online search: https://inel.corpora.uni-hamburg.de/NganasanCorpus/search
Nganasanisch (< Samojedisch < Uralisch) ist die nördlichste Sprache Eurasiens. Das INEL-Nganasan-Korpus basiert weitgehend auf dem Nganasan Spoken Language Corpus (v0.2, 2018), das an die INEL-Standards angepasst und mit neuen Texten ergänzt wurde. Der glossierte (durchsuchbare) Teil des Korpus umfasst Texte, die mit Quellmediendateien (sofern verfügbar) und annotierten Transkripten versehen sind. Der Archivteil des Korpus enthält nicht glossierte Texte, die entweder durch Audioaufnahmen (optional mit vorläufigen Transkriptionen) oder gescannte Seiten der Manuskripte oder Publikationen dargestellt werden.
- Glossierter (durchsuchbarer) Teil: 236 Texte, 34,872 Sätze, 221,747 Token
Gesamtdauer der Audioaufnahmen: 49 Std. 53 Min. - Archivteil: 98 Std. Audioaufnahmen (210 Texte) und 30 Manuskripte

Selkup
Brykina, Maria; Orlova, Svetlana; Wagner-Nagy, Beáta. 2021. INEL Selkup Corpus. Version 2.0. Publication date 2021-12-31. https://hdl.handle.net/11022/0000-0007-F4D9-1.
Online search: https://inel.corpora.uni-hamburg.de/SelkupCorpus/search

Das INEL Selkup-Korpus 2.0 besteht aus Texten aus dem Archiv von Angelina Ivanovna Kuzmina (1924–2002), die zwischen 1962 und 1977 in fast allen Regionen, in denen Selkupen lebten, eine große Menge an Material zur selkupischen Sprache (< Samojedisch < Uralisch) gesammelt hat. Die meisten Texte im Korpus stammen aus dem handschriftlichen Teil des Archivs, die übrigen aus Tonaufnahmen von A.I. Kuzmina, die im Rahmen des INEL-Projekts transkribiert und übersetzt wurden.
Der Archivteil des Korpus enthält Texte, die nicht glossiert wurden, aber einige davon verfügen über vorläufige Transkriptionen.
Korpusgröße
- Archivteil: 3 Manuskripte und 40 Audioaufnahmen
Gesamtdauer der Audioaufnahmen: 7 Std. 6 Min.
- Glossierter (durchsuchbarer) Teil: 352 Texte, 14,509 Sätze, 81,498 Token
Gesamtdauer der Audioaufnahmen: 3 Std. 34 Min.
Tavda Mansi
Sipőcz, Katalin & Wagner-Nagy, Beáta. 2025. INEL Tavda Mansi Corpus. Version 1.0. Publication date 2025-05-15. https://hdl.handle.net/11022/0000-0007-FE69-6.
Online search: https://inel.corpora.uni-hamburg.de/TavdaMansiCorpus/search
Die Analyse von Materialien aus der nun ausgestorbenen Tavda-Varietät des Mansischen (Ob-Ugrisch < Uralisch) wurde bereits von Norbert Szilágyi durchgeführt, jedoch erstellte er kein Korpus, das elektronisch durchsucht und ausgewertet werden konnte. In den im INEL-Korpus veröffentlichten Materialien unterscheiden sich die Analysen erheblich von Szilágyis Analyse. Zum Vergleich sind die von Szilágyi analysierten Texte dem Korpus beigefügt, und die von ihm gelieferten ungarischen Übersetzungen wurden beibehalten, jedoch an einigen Stellen korrigiert.
- Gesamt: 29 Texte, 2,042 Sätze, 11,879 Token