
VieLko – Vietnamesisches Lernerkorpus
Beitrag von Thi Bao Van Ho, Universität Leipzig
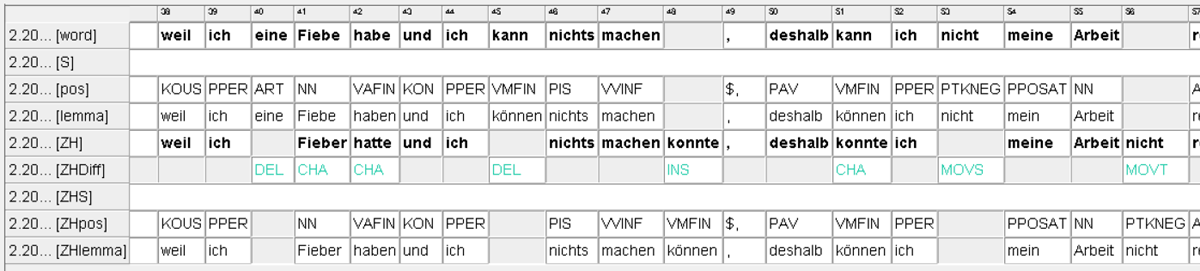
Das Vietnamesisches Lernerkorpus (VieLko) besteht aus Lernersprachdaten von vietnamesischen Germanistik-Studierenden, die mithilfe von EXMARaLDA auf vier Ebenen annotiert wurden, nämlich Tokenisierung, Lemmatisierung, Parts-of-Speech (POS) und erste Zielhypothese (ZH1). Der VieLko-Datenbestand umfasst sowohl schriftliche als auch mündliche Sprachdaten, die von Bachelor- und Masterstudierenden an zwei Hochschulen in Hanoi, Vietnam erhoben wurden. Dazu zählen u. a. Sprachprüfungstexte und -gespräche, Vorträge, Haus- und Seminararbeiten, sowie Abschlussarbeiten, die mit ausführlichen Metadaten über den sprachlichen Erwerb der Studierenden aufbereitet wurden. Aktuell bietet das VieLko-Team den Zugang zu den annotierten Daten durch eine lokal gespeicherte COMA-Datei mit begrenzter Such-Funktionalität, in naher Zukunft lässt sich das gesamte Korpus frei zugänglich auf dem DAKODA-Repositorium (https://dakoda.org/) bereitstellen, was nicht nur die Suche, sondern auch das Herunterladen von den Korpusdaten ermöglicht.
Weitere Informationen sind im folgenden Artikel zu finden:
Ho, Thi Bao Van (2023): VIELKO – Vietnamesisches Lernerkorpus. In: Korpora Deutsch als Fremdsprache 3(1), 152–158. https://doi.org/10.48694/kordaf.3739.