
VIELKO- Vietnamese learner corpus
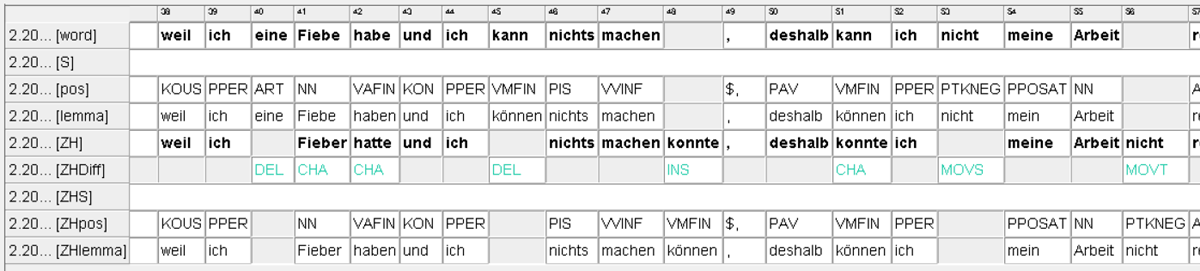
The Vietnamese Learner Corpus (VieLko) – comprising language data from Vietnamese students of German Studies – was annotated using EXMARaLDA on four levels: tokenisation, lemmatisation, parts of speech (POS) and first grade target hypothesis (ZH1). The corpus includes written as well as spoken data from bachelor and master students at two universities in Hanoi, Vietnam – ranging from written language exam texts, exam interviews, presentations, essays, seminar papers, to graduating theses. Aside from linguistic markups, the data were also encoded with a variety of metadata about the students’ language acquisition background. VieLko is currently accessible as a local copy in COMA format with limited corpus search functions and would soon be made publicly available on Project DAKODA’s repositorium (https://dakoda.org/), providing more search functionality and also downloadability of its data.
For more information about the corpus, please refer to the following article:
Ho, Thi Bao Van (2023): VIELKO – Vietnamesisches Lernerkorpus. In: Korpora Deutsch als Fremdsprache 3(1), 152–158. https://doi.org/10.48694/kordaf.3739.