Sprachtagging und orthografische Normalisierung von Texas-Deutsch
Blog post von Margo Blevins
Margo Blevins‘ Dissertation zum Thema „Sprachtagging und orthografische Normalisierung von gesprochenen gemischtsprachigen Daten, mit einem Schwerpunkt auf Texasdeutsch“ ist bei UT Electronic Theses and Dissertations [http://dx.doi.org/10.26153/tsw/43598] verfügbar.
Warum normalisieren?
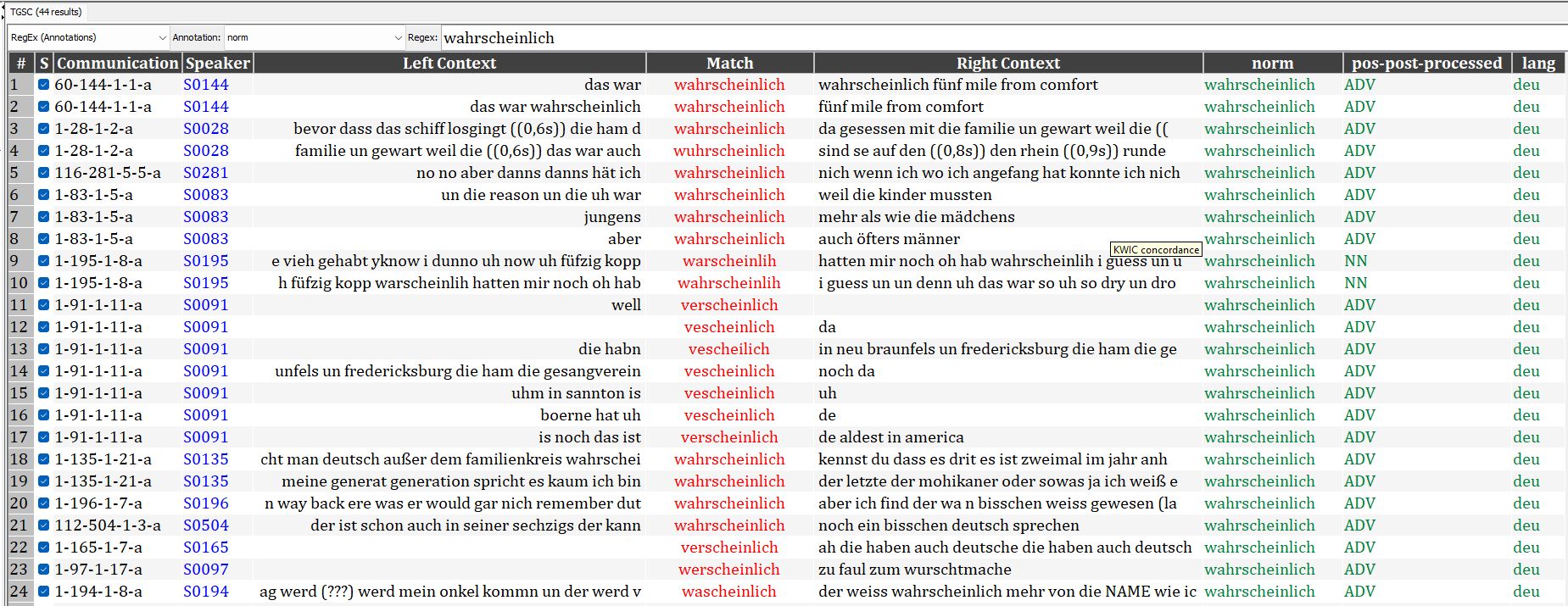
Gesprochene Daten aus Sprachkontaktsituationen sind äußerst vielfältig. Diese Heterogenität kann es erschweren, Vergleiche zwischen Korpora anzustellen und korpuslinguistische Werkzeuge auf die Daten anzuwenden. Auf einer noch grundlegenderen Ebene kann es einfach schwierig sein, das zu finden, wonach man sucht. Beispielsweise wurde in einem Datensatz von ca. 13 Stunden texanisch-deutscher Transkripte aus dem Texas German Dialect Archive (TGDA, tgdp.org/dialect-archive) das Wort wahrscheinlich auf 10 verschiedene Arten transkribiert: verscheinlich, wascheinlich, wuhrscheinlich, wahrscheinlich, wahrscheinlich, verscheinlich, vescheilich, warscheinlich, warscheinlih und werscheinlich. Wäre einE ForscherIn also daran interessiert, alle Fälle von wahrscheinlich zu finden, müsste er/sie entweder bereits alle mögliche verschiedenen Aussprache-/Transkriptionsweisen kennen oder würde zwangsläufig einen Teil der Daten übersehen, weil nicht klar ist, wie danach gesucht werden kann (oder dass überhaupt nach Schreibvarianten gesucht werden muss).
Diese Art der orthografischen Variation ist eine allgemein bekannte Herausforderung im NLP – sie kommt in Transkriptionen gesprochener Sprache, CMC wie Chat-Nachrichten und historischen Texten vor. Obwohl für andere Arten der linguistischen Annotation standardisierte Systeme vorgeschlagen wurden, wie z. B. die phonetische Transkription nach IPA (International Phonetic Association 1999), die orthografische Transkription, z. B. GAT (Selting 1998; Selting et al. 2009; Schmidt et al. 2015), und das POS-Tagging, z. B. STTS (Schiller et al. 1999; Westpfahl et al. 2017), gibt es kein standardisiertes System für die orthografische Normalisierung oder das Sprach-Tagging.
Für monolinguale Daten gibt es Tools zur orthografischen Normalisierung, aber in Sprachkontaktsituationen werden die Dinge etwas komplizierter. Zunächst einmal hängt es von der Interpretation auf Sprachebene ab, wie/ob die Schreibweise eines Wortes als „nicht standardisiert“ angesehen wird und wie die „Standard“-orthografische Form aussehen sollte. Wenn beispielsweise ein Transkript aus einer deutsch-englischen Kontaktsituation das Token <ham> enthält, ist es ohne weitere Informationen (z. B. Phonologie, Wortart usw.) nahezu unmöglich zu wissen, ob <ham> eine phonologisch reduzierte Version des deutschen Verbs haben darstellt oder ob es sich auf das englische Substantiv ham (‚Schinken‘) bezieht. Diese beiden Interpretationen würden zwangsläufig zu unterschiedlichen orthografischen Normalisierungen (und POS-Tags) führen.
Zweitens möchten ForscherInnen in vielen Sprachkontaktsituationen die Transkripte möglicherweise nicht so standardisieren, dass sie vollständig dem modernen Standarddeutsch entsprechen, solange jedes einzelne Token ein existierendes Lexem ist. Wenn zum Beispiel eine Person „mit die Frau“ sagt, ist es fraglich, ob dieser Satz in „mit der Frau“ normalisiert werden sollte, um der deutschen Standardgrammatik zu entsprechen. Bei der Normalisierung eines Textes ist es daher wichtig, klar abzugrenzen, (a) was normalisiert werden soll und was nicht, (b) wie es normalisiert werden soll und (c) warum es (auf diese Weise) normalisiert werden soll. Wo ist zum Beispiel die Grenze zwischen der Normalisierung phonologischer Variation und der Normalisierung grammatischer Variation?
Sprach-Tagging und orthografische Normalisierung von gesprochenen gemischtsprachigen Daten, mit einem Schwerpunkt auf Texasdeutsch

In Blevins (2022) entwerfe und implementiere ich Richtlinien für die systematische orthografische Normalisierung und das Sprach-Tagging von gesprochenen Texas-Deutsch Daten. Die Systeme sind so konzipiert, dass sie auch auf andere Nicht-Standard-Sprachvarietäten anwendbar sind.
Zwei Hauptziele für diese Systeme waren, die Daten leichter durchsuchbar zu machen und gleichzeitig die zukünftige NLP-Verarbeitung präziser zu machen (z.B. das (semi-)automatische Hinzufügen von Part-of-Speech-Tags oder Lemmata).
Meine Systeme basieren auf zehn bestehenden deutschen Varietätenkorpora (fünf exterritoriale deutschsprachige Minderheiten: das Ungarndeutsche Zweisprachigkeits- und Sprachkontaktkorpus; RuDiDat, ein Korpus für Russisch-Deutsch; das Unserdeutsch-Korpus; das DNAM-Korpus, eine Sammlung für Deutsch in Namibia, und natürlich das Texas German Dialect Project – sowie fünf weitere Korpora für gesprochene Varietäten des Deutschen: das Kiezdeutsch-Korpus, ein Korpus einer multiethnischen urbanen Varietät aus Berlin; BeMaTac, ein Korpus von Deutschlernenden, ebenfalls in Berlin beheimatet; das ArchiMob-Korpus, eine Sammlung dialektaler schweizerdeutscher Audiodateien aus Zürich; das SAGT-Korpus, ein Korpus türkisch-deutscher zweisprachiger Sprache aus Stuttgart; und FOLK, das Forschungs- und Lehrkorpus Gesprochenes Deutsch, das ein allgemeineres Korpus des gesprochenen Deutsch darstellt).
Das Texas German Sample Corpus TGSC
Als Fallstudie für die Umsetzung der von mir vorgeschlagenen Normalisierungs- und Sprachkennzeichnungsrichtlinien habe ich ein Korpus des Texas-Deutschen unter Verwendung von Transkriptionen von Gesprächsinterviews aus dem Texas German Dialect Project (TGDP, Boas et al. 2010) erstellt, siehe Blevins (2022). Die ca.13 Stunden Audio für dieses „Texas German Sample Corpus“ (TGSC) wurden als Zufallsstichprobe so ausgewählt, dass sie proportional repräsentativ für die ersten 600 texanisch-deutschen Sprecher sind, die für das TGDP interviewt wurden. Die Annotationen wurden mit dem EXMARaLDA Partitur-Editor vervollständigt.

Automatisierung von Sprachkennzeichnung und Normalisierung

In Zusammenarbeit mit Thomas Schmidt konnten wir die mit Sprach-Tags versehenen und normalisierten Formen zusammen mit den tokenisierten Transkriptionen in der TGSC nutzen, um ein automatisches Tool zu trainieren, das diese beiden Annotationsschichten sowie Part-Of-Speech und Lemmata hinzufügt. Unter Verwendung der Trainingsdaten der TGSC (für Normalisierung und Sprach-Tagging) und des mit FOLK trainierten STTS 2.0 Taggers (für Lemmatisierung und POS-Tagging) ergaben sich folgende Fehlerquoten:
- eine Fehlerquote von 6,5% für die Normalisierung (vergleichbar mit FOLK)
- eine Fehlerquote von 5,0 % bei der Sprachkennzeichnung (nicht relevant für FOLK)
- eine Fehlerquote von 14,1 % beim POS-Tagging (6 % bei FOLK).
Diese Werkzeuge und Workflows wurden dann verwendet, um zu allen bestehenden Transkripten im TGDA (ca.150 Stunden) eine tokenisierte Transkription, Sprach-Tags, Normalisierung, POS und Lemma hinzuzufügen.
Die Verwendung des EXMARaLDA Partitur-Editors, des Corpus Managers und von EXAKT war ein entscheidender Schritt bei der Erstellung der TGSC, bei der Suche in der TGSC und bei der Verwendung der Annotationen in der TGSC, um Werkzeuge zu trainieren, mit denen das TGDA um mehrere Ebenen zusätzlicher Informationen erweitert werden konnte. Die Transkripte werden dadurch für die ForscherInnen deutlich nützlicher.