Language-tagging and orthographic normalization of Texas German
Margo Blevins‘ dissertation on “The language-tagging & orthographic normalization of spoken mixed-language data, with a focus on Texas German” is available from UT Electronic Theses and Dissertations [http://dx.doi.org/10.26153/tsw/43598].
Blog post by Margo Blevins
Why normalize?
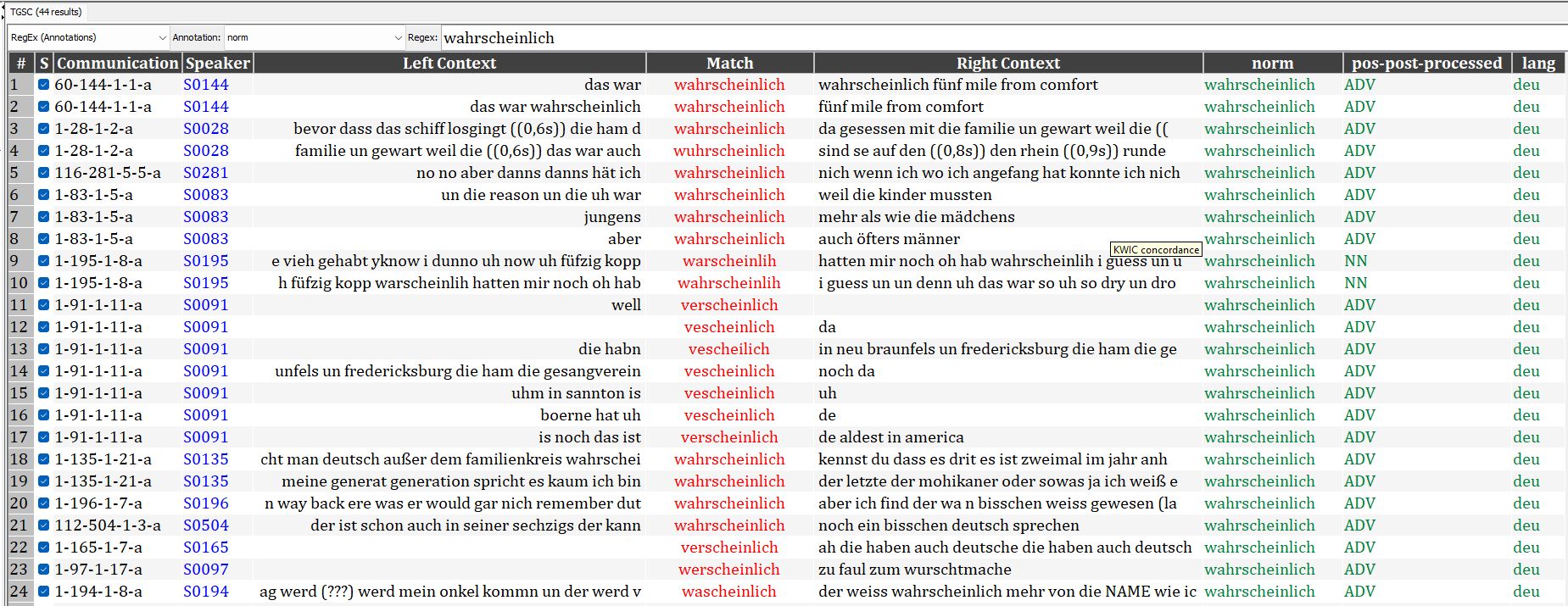
Spoken data from language-contact situations is extremely varied. This heterogeneity can make it difficult to make comparisons across corpora, and to use corpus linguistic tools on the data. On an even more basic level, it can simply make it difficult to find what you are looking for. For example, in a set of ~13 hours of Texas German transcripts from the Texas German Dialect Archive (TGDA, tgdp.org/dialect-archive), the word wahrscheinlich ‘perhaps/probably’ was spelled in 10 different ways: verscheinlich, wascheinlich, wuhrscheinlich, wahrscheinlich, wahrscheinlich, verscheinlich, vescheilich, warscheinlich, warscheinlih, and werscheinlich. Therefore, if a researcher were interested in finding all of the instances of wahrscheinlich, they would either have to already know all the different ways in which it had been pronounced / transcribed, or inevitably overlook a portion of data because they did not know how to look for it (or that they needed to look for spelling variations at all).
This kind of orthographic variation is a commonly known challenging in NLP – it occurs in transcriptions of spoken language, computer-mediated-communication such as chat messages, and historical texts. While standardized systems have been proposed for other kinds of linguistic annotation, such as phonetic transcription, e.g., IPA (International Phonetic Association 1999); orthographic transcription, e.g., GAT (Selting 1998; Selting et al. 2009; Schmidt et al. 2015); and POS-tagging, e.g., STTS (Schiller et al. 1999; Westpfahl et al. 2017), there is no standardized system for orthographic normalization or language-tagging.
For monolingual situations, there are tools available to orthographically normalize text, but in language-contact situations, things get a little more complicated. First of all, how/whether the spelling of a word is deemed ‘non-standard’ and identifying what the ‘standard’ orthographic form should be is reliant on language-level interpretations. For example, if a transcript from a German-English contact situation contained the token <ham>, without further information (e.g., phonology, part of speech, etc.), it is close to impossible to know whether <ham> represents a common phonologically reduced version of the German verb haben ‘to have,’ or whether it refers to the English noun ham, referring to a pork product. These two interpretations would necessarily lead to different orthographic normalizations (and part-of-speech tags, for that matter).
Secondly, in many language-contact situations, researchers may not want to standardize transcripts to completely conform to modern standard German, as long as each individual token is an existing lexeme. For example, if a person were to say mit die Frau ‘with the-NOM/ACC woman,’ it is debatable whether that phrase should be normalized to mit der Frau ‘with the-DAT woman’ to conform to standard German grammar. When normalizing a text, it is therefore important to clearly delineate what should and should not be normalized, how it should be normalized, and why it should be normalized (in that way). Where, for example, is the line between normalizing phonological variation and normalizing grammatical variation?
The language-tagging & orthographic normalization of spoken mixed-language data, with a focus on Texas German

In Blevins (2022) I construct and implement guidelines for the systematic orthographic normalization and language-tagging of Texas German spoken data. The systems are designed to also be applicable to other non-standard language varieties.
Two main goals for these systems were to make the data more easily searchable, while also making future NLP processing more accurate (e.g., the (semi-)automatic addition of part-of-speech tagging or lemma).
My systems are based on ten existing German variety corpora (five exterritorial German-language minorities: the Ungarndeutsches Zweisprachigkeits- und Sprachkontaktkorpus of Hungarian German; RuDiDat, a corpus of Russian German; the Unserdeutsch corpus; the DNAM corpus, a collection of Namibian German, and of course the Texas German Dialect Project – as well as five other corpora of spoken varieties of German: the Kiezdeutsch corpus, a corpus of a multiethnic urban variety from Berlin; BeMaTac, a corpus of learner German, also housed in Berlin; the ArchiMob corpus, a collection of dialectal Swiss German audio based in Zurich; the SAGT corpus, a corpus of Turkish-German bilingual speech from Stuttgart; and FOLK, the Forschungs- und Lehrkorpus Gesprochenes Deutsch, which is a more general corpus of spoken German).
The Texas German Sample Corpus TGSC
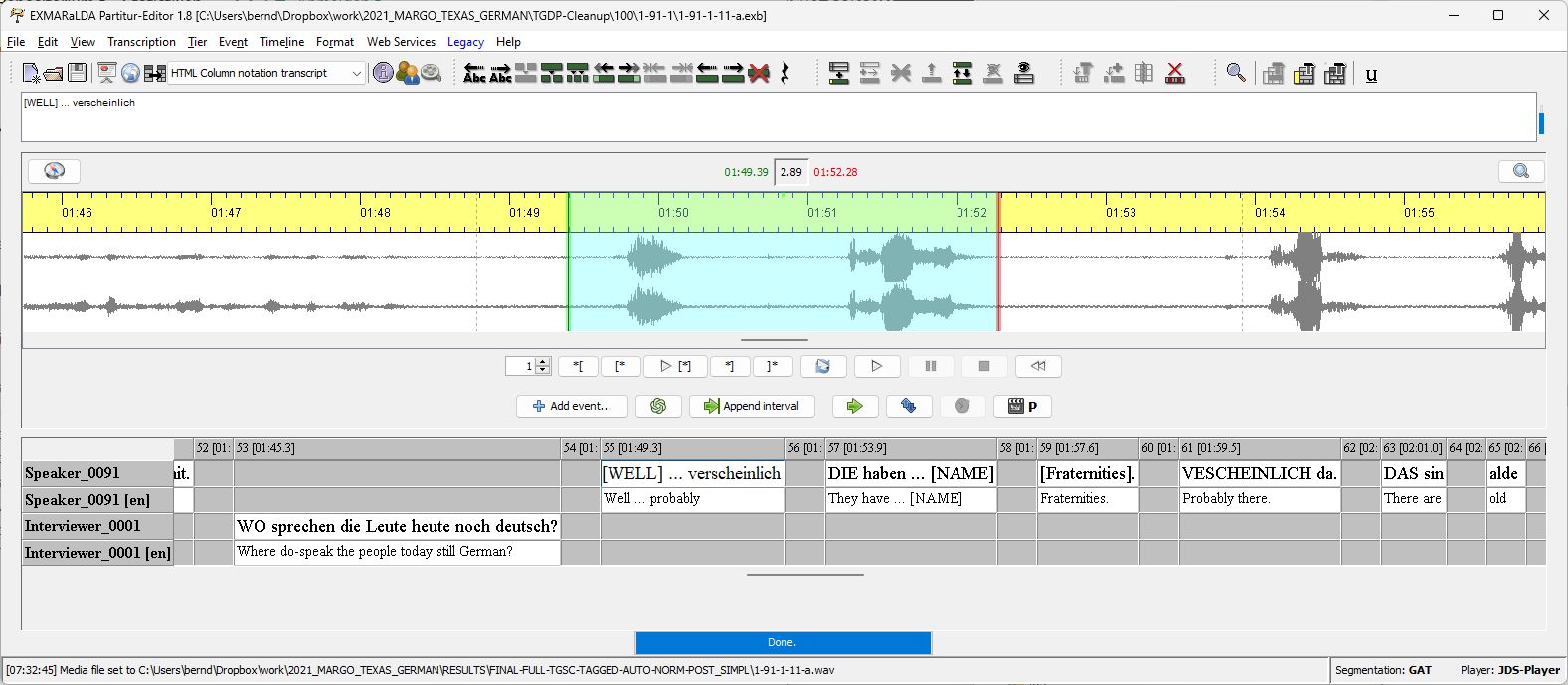
As a case-study for the implementation of my proposed normalization and language-tagging guidelines, I constructed a corpus of Texas German using transcriptions of conversational interviews from the Texas German Dialect Project (TGDP, Boas et al. 2010), see Blevins (2022). The ~13 hours of audio for this “Texas German Sample Corpus” (TGSC)” was randomly selected in such a way that it is proportionally representative of the first 600 Texas German speakers interviewed by the TGDP, and the annotations were completed using the EXMARaLDA Partitur-Editor.

Automating language tagging and normalization

In a collaboration with Thomas Schmidt, we were able to use the language-tagged and normalized forms, along with the tokenized transcriptions in the TGSC help train an automatic tool to add those two annotation layers, as well as part-of-speech and lemma. Using the training data of the TGSC (for normalization and language tagging) and the FOLK-trained STTS 2.0 tagger (for lemmatization and POS tagging), the resulting error rates were as follows:
- an error rate of 6.5% for normalization (comparable to FOLK)
- an error rate of 5.0% for language tagging (not relevant for FOLK)
- an error rate of 14.1% for POS tagging (6% for FOLK)This is for a fully automated annotation chain on the TGSC evaluation data.
This is for a fully automated annotation chain on the TGSC evaluation data.
| Without post-processing | With post processing | |
| Manual Normalization and Language tagging | 24% | 11.6% |
| Automatic Normalization and Language tagging | 27% | 14.1% |
These tools and workflows were then used to add a tokenized transcription, language-tags, normalization, part-of-speech, and lemma to all of the existing transcripts in the TGDA (~150 hours).
Using the EXMARaLDA Partitur-Editor, Corpus Manager and EXAKT was a vital, pivotal step in the creation of the TGSC, search the TGSC, and use the annotations within the TGSC to train tools to then add multiple layers of integral information to the TGDA, making the transcripts immeasurably more useful to researchers.