

Unserdeutsch-Korpus in der DGD
Von Siegwalt Lindenfelser.
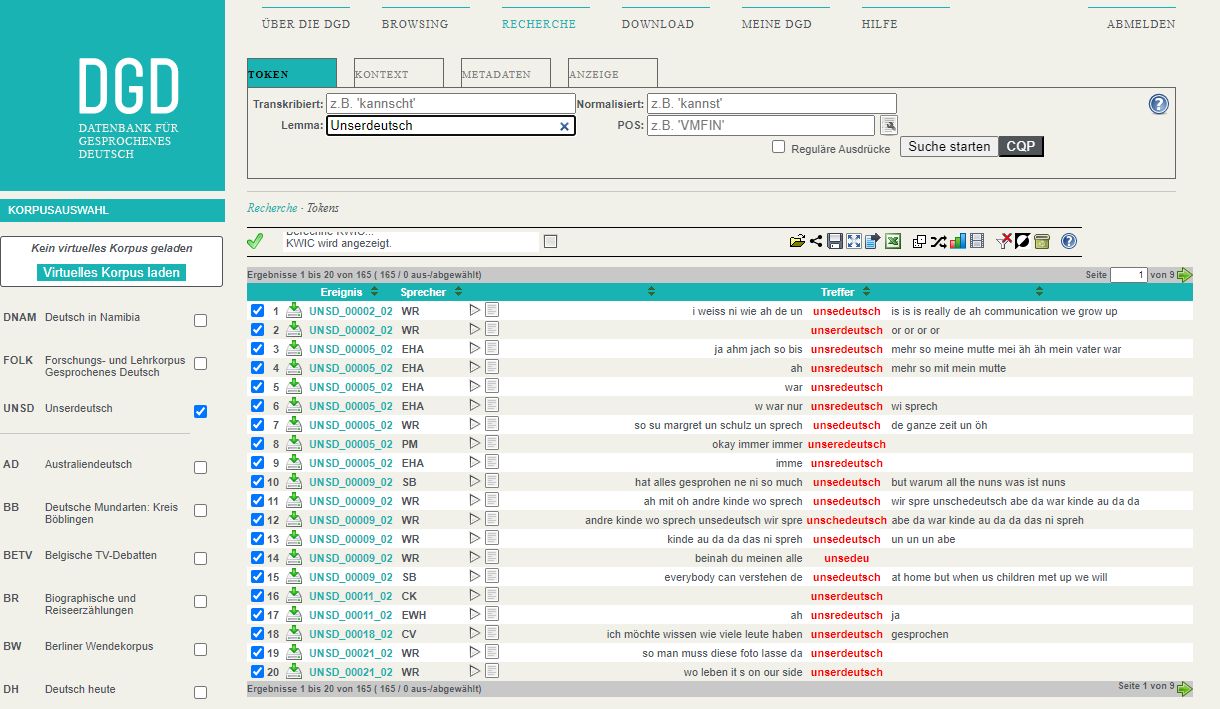
Mit Version 2.21 der Datenbank für Gesprochenes Deutsch (DGD) wurde Mitte Januar 2024 das Korpus „Unserdeutsch“ (UNSD) am IDS Mannheim erstveröffentlicht. Außer über die DGD ist das Korpus auch über die ZuMult-Tools am IDS zugänglich.
Aufbereitung des Unserdeutsch-Korpus mit den EXMARaLDA-Tools

Das Korpus wurde von der Transkription der Sprachaufnahmen über die Normalisierung und Lemmatisierung der Transkripte bis hin zum Part-of-Speech-Tagging vollständig mit EXMARaLDA-Tools erstellt. Der Korpusaufbau im DFG-Projekt „Unserdeutsch (Rabaul Creole German): Dokumentation einer stark gefährdeten Kreolsprache in Papua-Neuguinea“ (Prof. Péter Maitz, Prof. Werner König) an der Universität Augsburg und später an der Universität Bern erfolgte in enger Kooperation mit dem Archiv für Gesprochenes Deutsch (AGD) sowie dem Entwickler der EXMARaLDA-Tools, der zu dieser Zeit in Personalunion auch die Leitung von AGD und des übergeordneten Programmbereichs Mündliche Korpora am IDS innehatte. Dabei flossen aus projektspezifischen Bedürfnissen wiederum Anregungen zur Weiterentwicklung in einzelne EXMARaLDA-Tools zurück.
Das erste und wahrscheinlich letzte größere Korpus zum Unserdeutsch
Das nun veröffentlichte Unserdeutsch-Korpus stellt Audioaufnahmen, cGAT-Transkripte und Metadaten zu mehr als 50 Ereignissen im Umfang von über 50 Stunden in der gleichnamigen einzigen deutschbasierten Kreolsprache bereit. Unserdeutsch ist kritisch gefährdet und wird nur noch von unter 100 älteren Menschen an der Ostküste Australiens und in Papua-Neuguinea gesprochen. Die zwischen 2014 und 2018 erhobenen biographischen Interviews, aus denen das Korpus hauptsächlich besteht, dokumentieren eine durch intensiven Sprachkontakt geformte, strukturell einzigartige Varietät und gleichzeitig inhaltlich ein Stück deutscher Kolonialgeschichte.
Der Entstehungsort von Unserdeutsch: Missionsstation Vunapope, Papua-Neuguinea
(Foto: Siegwalt Lindenfelser 2017)

Unserdeutsch entstand zu Beginn des 20. Jahrhunderts unter ethnisch gemischten Kindern und Jugendlichen in Internaten der katholischen Herz-Jesu-Missionare (MSC) in Vunapope auf der Insel Neubritannien im Bismarck-Archipel. Dieser war von 1884 bis 1914 Teil der Kolonie Deutsch-Neuguinea. Die Kinder und Jugendlichen, meist Halbwaisen, wurden im Zuge der Christianisierungspolitik der MSC – nicht immer freiwillig oder im Einverständnis der indigenen Mutter – an die Missionsstation gebracht und dort auf Deutsch beschult. Sie brachten überwiegend eine frühe Form des Tok Pisin als Erstsprache mit, der heutigen Verkehrs- und Nationalsprache Papua-Neuguineas, die selbst ein englisch-basiertes Pidginkreol ist. Ethnisch entwurzelt und unter dem Zwang, trotz noch nicht ausreichend vorhandener Kompetenz Deutsch sprechen zu müssen, entstand so im Zusammenspiel von Sprachkontakt und L2-Effekten Unserdeutsch – und stabilisierte sich, obwohl später auch noch eine Kompetenz des Standarddeutschen in Wort und Schrift erworben wurde. Durch Verheiratung untereinander wurde Unserdeutsch bereits an die zweite Generation als Erstsprache weitergegeben, überstand die Wirren zweier Weltkriege und wurde später noch durch verstärkten Sprachkontakt zum Englischen weiter geformt (Näheres zur Genese von Unserdeutsch vgl. Lindenfelser 2021). Die letzten verbliebenen Sprecher und Sprecherinnen von Unserdeutsch weisen keine parallele Standardkompetenz mehr auf und zeigen vielfach bereits mehr oder weniger deutliche Attritionserscheinungen, da sie die Sprache in einem dominant englischsprachigen Umfeld kaum mehr verwenden.
Herausforderungen bei der Erschließung
Der Aufbau des Unserdeutsch-Korpus erforderte aufgrund des intensiven Sprachkontakts zwischen drei Sprachen in den Daten – Unserdeutsch, Englisch, Tok Pisin – eine Reihe vorgelagerter Entscheidungen bei der Transkription und Annotation (Näheres zum Korpusaufbau vgl. Götze et al. 2017). Die Transkription erfolgte dabei prinzipiell nach cGAT unter Verwendung des Partitur-Editors, wobei das Prinzip der alleinigen Kleinschreibung im Minimaltranskript an einer Stelle durchbrochen wurde, um den Unterschied zwischen Unserdeutsch i ‘ich’ und Englisch I ‘ich’ abbilden zu können. Die Tokenisierung der Transkripte für den Import in OrthoNormal und die dortige Annotation wurde über den FOLKER-Editor vorgenommen. Normalisierung, Lemmatisierung und Part-of-Speech-Tagging schließlich erfolgten im EXMARaLDA-Tool OrthoNormal. Dabei wurde zunächst eine kritische Menge von Transkripten auf Basis einer Parameterdatei für Gesprochenes Deutsch halbautomatisch vorgetaggt und dann manuell zeitaufwändiger korrigiert. Anschließend wurden durch den Entwickler eine speziell angepasste Parameterdatei für Unserdeutsch auf dieser Grundlage trainiert sowie Post-Processing-Regeln implementiert, die den manuellen Korrekturaufwand ab diesem Zeitpunkt deutlich reduzierten. Das POS-Tagging in Unserdeutsch erfolgte auf Basis des STTS-2.0-Tagsets unter Berücksichtigung projektspezifischer Konventionen. Dazu gehörte einerseits die Einführung neuer Tags (PTKAM für die Aspektpartikel am im am-Progressiv, der in Unserdeutsch stark grammatikalisiert ist, sowie PL für den analytischen Pluralanzeiger alle in Unserdeutsch: alle Haus ‘Häuser’). Andererseits gehörte dazu die Erweiterung bestehender Tags (eine Spezifizierung des Tags FM ‚Fremdsprachliches Material‘ nach Sprache, bspw. FM-TP für Tok Pisin) oder die Reduktion bestehender Tags (hier die Unterspezifizierung der verbalen Tags durch Weglassung der Angabe zur Finitheit, die für Unserdeutsch strukturell problematisch ist – VVFIN und VVINF sind damit etwa zu einem Tag VV verschmolzen). Auch dies spielte eine Rolle bei der Anpassung der Parameterdatei und der Formulierung von Post-Processing-Regeln nach den spezifischen Bedürfnissen des Projekts. Zur Erleichterung der manuellen Nachkorrektur wurde während des Korpusaufbaus auf Wunsch aus dem Projekt durch den Entwickler von OrthoNormal neben weiteren kleinen Komfort-Features beispielsweise eine fortlaufende Tokenzählung in das Tool implementiert.
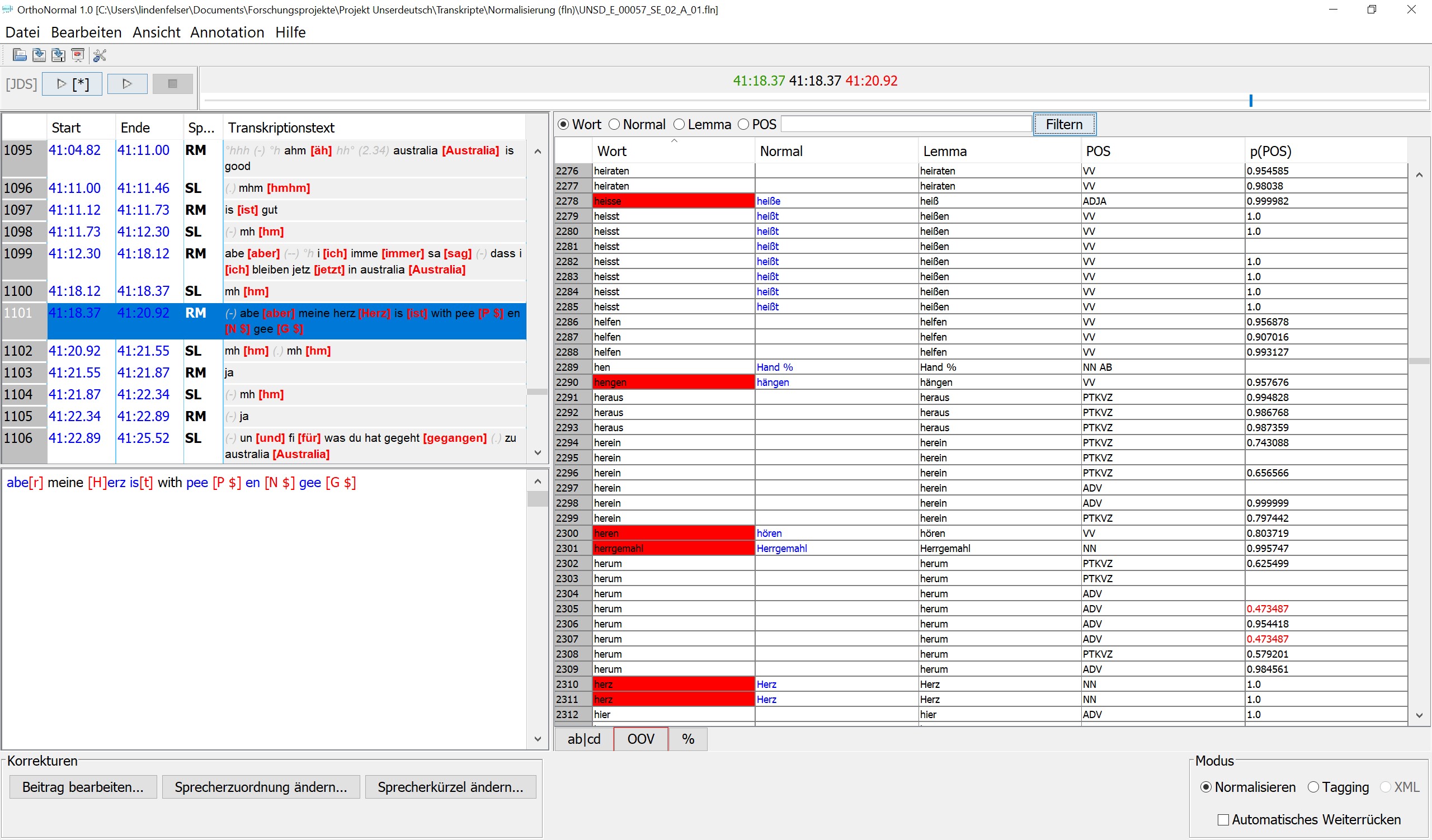
Annotation eines tokenisierten Unserdeutsch-Transkripts in OrthoNormal
Für projektinterne Recherchen wurde vor der Übergabe der Korpusdaten an das IDS Mannheim auch die EXMARaLDA-Tools COMA zur Erstellung eines lokal durchsuchbaren Korpus sowie EXAKT zur Recherche innerhalb des lokal erstellten Korpus verwendet. Unserdeutsch ist damit ein Anwendungsfall, der die Funktionalitäten des EXMARaLDA-Systems in ihrer breiten Vielfalt verwendet und dabei zugleich zu ihrer Weiterentwicklung beigetragen hat, insbesondere mit Blick auf die Mehrsprachigkeit der Daten und das typologisch abweichende Profil der Kreolsprache.
Die weitere Aufbereitung dieser Daten am AGD und ihre Veröffentlichung über die DGD ermöglicht nun vertiefte, insbesondere auch quantitativ fundierte Forschungen zu Unserdeutsch. Die Daten halten dabei noch viel unausgeschöpftes Potenzial für weitere linguistische Erkenntnis rund um Sprachkontakt, Sprachvariation und Sprachwandel bereit, aber auch darüber hinaus, beispielsweise für Forschungen zum Spracherwerb oder zur Missions-, Kolonial- und Postkolonialgeschichte.
Angeführte Literatur
Götze, Angelika / Lindenfelser, Siegwalt / Lipfert, Salome / Neumeier, Katharina / König, Werner / Maitz, Péter (2017): Documenting Unserdeutsch (Rabaul Creole German): A workshop report. In: Maitz, Péter / Volker, Craig A. (Hrsg.): Language Contact in the German Colonies: Papua New Guinea and beyond [= Special issue of Language and Linguistics in Melanesia], 91–142. [https://boris.unibe.ch/121389/]
Lindenfelser, Siegwalt (2021): Kreolsprache Unserdeutsch. Genese und Geschichte einer kolonialen Kontaktvarietät. Berlin/Boston: de Gruyter. [https://doi.org/10.1515/9783110714067]