

Literarische Umschrift für gesprochenes Arabisch
Lösungswege zum Umgang mit Mehrsprachigkeit und Mehrschriftigkeit in gesprächsanalytischen Transkripten
Ein Blog-Beitrag von Rahaf Farag (Universität Mainz / Leibniz-Institut für Deutsche Sprache)

Kürzlich ist die Dissertation von Rahaf Farag unter dem Titel
Computergestützte Transkription arabisch-deutscher Gesprächsdaten: ein methodischer Beitrag zur Untersuchung gedolmetschter Gespräche
(= FTSK. Publikationen des Fachbereichs Translations-, Sprach- und Kulturwissenschaft der Johannes Gutenberg-Universität Mainz in Germersheim, Band 75) im Peter Lang Verlag erschienen.
Das Datenkorpus, auf dem die Dissertation basiert, ist beim Zentrum für nachhaltiges Forschungsdatenmanagement der Universität Hamburg veröffentlicht:
Meyer, Bernd / Farag, Rahaf. (2023). Telephone Interpreting German-Arabic (TIGA) / Telefondolmetschen Arabisch-Deutsch (TeDo) (Version 1.0) [Data set].
Computergestützte Transkription empirischer Sprachdaten ist ein Grundinstrument verschiedener linguistischer Ansätze. Die schriftbasierte (orthografische) Rekonstruktion gesprochener Sprache gestaltet sich bekanntlich schwierig, wenn die Daten mehrsprachige, varietätenreiche und polydialektale Interaktionsprozesse dokumentieren. Je unterschiedlicher die Schriftsysteme und je lückenhafter die orthografische Kodifizierung der standardfernen Sprachformen, desto schwieriger die Rekonstruktion. Dies gilt zum Beispiel für die Transkription arabisch-deutscher Gespräche. Wie lässt sich gesprochenes Arabisch gesprächsanalytisch verschriften und übersetzen? Welche Möglichkeiten bieten lateinbasierte Umschriften? Diese Arbeit schlägt eine Systematik auf Grundlage von Beratungsgesprächen vor, die per Telefon gedolmetscht wurden.
Grundlegende Herausforderungen bei der gesprächsanalytischen Aufbereitung von Gesprächsdaten mit arabischsprachigen Anteilen
Die Transkription mehrsprachiger Gespräche mit arabischsprachigen Anteilen beschäftigt mich seit geraumer Zeit. Sie entsprang dem Interesse an der gesprächsanalytischen Erforschung mehrsprachiger, bisweilen dolmetschgestützter Interaktionen, speziell zu sprachlich-kommunikativen Verfahren beim Telefondolmetschen Arabisch-Deutsch. Das Bedürfnis, eine Lösung für bislang wenig beachtete Probleme arabischsprachiger Transkription zu finden, wurde im Laufe der Zeit immer stärker und schließlich, am Ende eines langen Prozesses, zur festen Überzeugung, dass die speziellen Forschungszwecke derzeit ohne eine lateinschriftige Transkription des Arabischen nicht realisierbar sind. Entscheidend waren die eingeschränkten transkriptionstechnischen Möglichkeiten bei der Überführung der Zeitlichkeit eines Gesprächs in die Räumlichkeit eines Transkripts. Es hatte sich unter anderem herausgestellt, dass die Zusammenführung der jeweils entgegengesetzten Schreibrichtungen des Arabischen und des Deutschen nicht nur grafische Konsequenzen nach sich zieht, sondern auch die Analysierbarkeit der Transkripte, etwa bei Untersuchung von Interaktionsdynamiken und anderweitig zeitgebundenen Phänomenen, be- oder sogar verhindert.
Linksläufigkeit arabischer Schrift vs. Rechtsläufigkeit deutscher Schrift
Eine zentrale Schwierigkeit bei der computergestützten Transkription von arabischen Daten ist in der Linksläufigkeit der arabischen Schrift begründet. Die existierenden Transkriptionstools, einschließlich EXMARaLDA, wurden für rechtsläufige Schriftsysteme entwickelt. Bereitgestellte Transkriptionsoberflächen lassen sich im Grunde nicht beliebig ausrichten. Transkribent*innen haben sich also an der vorgegebenen Struktur zu orientieren, wie etwa der Links-Rechts-Abfolge der Segmente auf horizontaler Ebene entlang der rechts freilaufenden Zeitachse und der Oben-Unten-Anordnung der Spuren, die jeweils eine Handlungslinie und gegebenenfalls ihre Annotationen abbilden. Das Prinzip einer fortlaufenden Zeit- und Handlungslinie sieht eine gleichgerichtete Anordnung der Ereignisse vor, die mit der sukzessiven Entfaltung interaktionaler Prozesse parallel laufen soll. Nichtsdestotrotz lassen sich die feststehenden Grundeinheiten (Spuren, Segmente) prinzipiell frei in beide Richtungen transkribieren, was ich im folgenden Fallbeispiel an eigenen Daten aus dem Telefondolmetschprojekt erprobte (Farag 2023: 193).

K3 ist ein syrischer Klient mit subsidiärem Schutz. Er lebt in einer süddeutschen Kleinstadt und versucht vergeblich, seine Familie nach Deutschland nachzuholen. Beim analog vor Ort stattfindenden Beratungsgespräch mit einer Deutsch sprechenden Sozialberaterin (B1), die allerdings im obigen Ausschnitt nicht spricht, ist K3 auf die nur akustisch wahrnehmbare Verdolmetschung des nicht physisch präsenten Telefondolmetschers (TD2) angewiesen. Im Auszug schildert der Klient, welche Probleme er im Asylverfahren erlebt hat und wie sie die Wiedervereinigung mit seiner Familie erschweren. Um das Augenmerk zunächst einmal auf die Darstellungsweise verbaler Handlungen zu richten, habe ich die deutschen Übersetzungen bewusst ausgeblendet. Die blauen Pfeile geben die Leserichtung vor.
Wie aus dem Auszug zu ersehen ist, ermöglicht der EXMARaLDA Partitur-Editor eine horizontal linksläufige Schreibrichtung und somit eine bidirektionale Textrichtung sowie eine tridirektionale Leserichtung bei sich überlappenden Einheiten und parallelen Annotationen (links-rechts, rechts-links, oben-unten). Probleme der Darstellung zeigen sich auf den ersten Blick an ständig auftretenden Unterbrechungen des Leseflusses, die einzelne Handlungsabfolgen, interaktive Bezüge und schließlich den gesamten Interaktionsprozesses schwer nachvollziehbar machen. In der fortlaufenden Fläche ist jedes arabischschriftige Segment stets linksläufig zu lesen. Man setzt also beim Lesen am rechten Segmentrand an, hört am linken Segmentrand auf und blickt wieder nach rechts, um die Lektüre am nächsten rechten Rand fortzusetzen usw., ganz gleich, ob das Ende eines Segments auch ein Äußerungsende markiert oder nicht. Zudem rufen die Komprimierung in ein DIN-A4 Seitenformat und die entsprechenden Seitenumbrüche nicht nur eine versetzte Anordnung der Beiträge, sondern auch optische Verzerrungen (selbst in der Schrift) hervor.
Neben der versetzten Wiedergabe der Segmente zeigen sich weitere Defizite in der zeitlichen Strukturierung des Transkripts im Laufe der Analyse, wie eine verdrehte bzw. konfuse Wiedergabe der Entwicklungsrichtung der Interaktion und der einzelnen Handlungslinien jedes Aktanten. Der Zeitpunkt, an dem ein Segmentende markiert wird, korrespondiert nicht mit dem eingetragenen Text. Somit sind turnübergaberelevante Stellen, an denen sich der Sprecher- und Hörerstatus ändert oder ändern könnte, zum falschen Zeitpunkt aligniert – zumindest aus der Perspektive eines Arabisch verstehenden Lesers. An einem späteren Zeitpunkt verzeichnete Phänomene (Pausen, Äußerungsabschlüsse, Unterbrechungen etc.) stehen nach der Logik des Editors bereits am Anfang einer Äußerung bzw. eines Segments. Der Lesefluss stockt stärker, wenn ein Beteiligter dem Sprecher ins Wort fällt und es ihm gar abschneidet, um eine Turnübergabe zu erzwingen. Verzerrungen in der Darstellung und die defizitäre zeitliche Alignierung fallen vor allem in den Segmenten 168, 169‒170 und 174‒178 besonders stark auf. Die bidirektionale Darlegung in der angeführten Form kann deshalb nicht als Arbeitsgrundlage dienen.
Aufgrund mannigfaltiger Unstimmigkeiten in der Darstellung trotz Bemühungen um eine zweckdienliche Zusammenführung beider Schriftsysteme im Transkript galt es nun zu überprüfen, inwieweit eine lateinschriftige Transkription der arabischen Anteile die besagten Defizite beheben kann. Die Entscheidung fiel – aus analytischen, transkriptionspraktischen oder publikationstechnischen Gründen – für eine monoschriftige Transkription und eine romanisierte Schreibung arabischsprachiger Handlungen. Es stellte sich nunmehr die Frage nach der Wahl eines geeigneten Umschriftsystems. Bei der Suche wurde mir immer mehr bewusst, dass ich mich mit jedem Schritt erneut auf methodisches Neuland begebe, das zwar überaus spannend ist, zugleich aber hochgradig komplexe Anforderungen zu berücksichtigen hat und die Diskussion mithin strittiger Ansätze und problematischer Praktiken sowie blinder Flecke anstößt.
Eine gesprächsanalytisch motivierte Systematik zur Transkription arabischsprachiger Gesprächsdaten
Die Verschriftung des gesprochenen Arabisch ist aufgrund der kaum konventionalisierten Schreibung standardferner Varietäten und der unzureichenden Beschäftigung mit sprechsprachlichen Phänomenen (z. B. Diskursmarker, Interjektionen, Verzögerungslaute etc.) schwierig. Die im deutsch- und englischsprachigen Raum bewährten Umschriftsysteme entstammen häufig philologischen sowie historischen bzw. historisch-geografischen Arbeiten und setzten sich, über die wissenschaftlichen Schriften hinaus, besonders in den konventionalisierten Bereichen Bibliotheks- und Informationsmanagement, Lexikografie und Geografie (speziell Kartografie) durch. Demnach orientieren sie sich primär an der Standardlautung und ‑schreibung und sind somit auf die Wiedergabe der Geschriebensprachlichkeit zugeschnitten. Sie streben nach (normativer) Einheitlichkeit und Stringenz, was ihre Anwendung entsprechend kompliziert macht.
Mit Ausnahme der aus der Arabistik, der arabischen Dialektologie und Lexikografie, aber auch aus der Phonetik in die Soziolinguistik eingeführten Umschriften gibt es offenbar keine gesprächsanalytischen, eher orthografischen Umschriftsysteme für das Arabische die (primär) der Erschließung und der Erforschung von Sprache-im-Alltag bzw. -in-Interaktion dienen. Das könnte wiederum daran liegen, dass die empirische Arbeit mit arabischen Gesprächsdaten (jenseits der Arabistik, Dialektologie, Soziolinguistik, Computerlinguistik, Spracherwerbsforschung) nicht auf eine lange Tradition zurückblickt. Es stehen nämlich so gut wie keine allgemein nutzbaren, leicht auffindbaren Gesprächskorpora zur Verfügung. Den veröffentlichten Forschungsdaten, die in der Regel lediglich als Transkriptbeispiele dienen, fehlt es bisweilen an der nötigen Transparenz. Vertretbare Lösungsansätze ließen sich daher nur schwer finden.
Die aufgestellten Maximen lauten: Lesbarkeit, Verständlichkeit und Einheitlichkeit bei größtmöglicher Authentizität. Die Eignung des Umschriftsystems für die Partiturdarstellung und die Orientierung an den HIAT-Konventionen waren zwar maßgebend, das System sollte sich aber auch mit anderen Darstellungsformaten und Konventionen vereinbaren lassen.
Die DMG-Umschrift stellt, im Grunde genommen, das notwendige maschinell verarbeitbare Inventar an Grundzeichen zur Verfügung, um eine gleichgerichtete Transkription zu ermöglichen. Zudem gelingt es mit dem DMG-Zeicheninventar leichter, eindeutige Graphem-Phonem-Beziehungen im lateinischen Schriftbild herzustellen, um jene verständnishemmenden Ambiguitäten zu vermeiden, die oft bei nicht konventionalisierten Umschriften zu beklagen sind.
Nichtsdestotrotz musste das DMG-Inventar optimiert und erweitert werden, um standardferne gesprochensprachliche und regionalsprachliche Formen der konsonantischen und vokalischen Aussprache zu rekonstruieren und systematisch festzuhalten. Des Weiteren erarbeitete ich eine Systematik zur Wiedergabe der verbalen Äußerungen, wobei diese Systematik, über die Verwendung der Zeichen an sich hinaus, der Anwendbarkeit, Handhabbarkeit und Rezipierbarkeit der Umschrift und der Vermittelbarkeit der Transkripte insgesamt Rechnung zu tragen versucht. Es sollte sich um eine Systematik handeln, die allgemein zu berücksichtigende Phänomene und ihre grafische Abbildung festlegt, bewusste Abweichungen von schriftsprachlichen Standards und DMG-Zeichen kodifiziert, die Typografie lesbar gestaltet, die Schreibung vereinheitlicht und Probleme löst, die in dialektologischen Arbeiten entweder nicht behandelt oder unterschiedlich bewältigt werden, oder deren Lösung sich nicht immer mit den definierten gesprächsanalytischen Anforderungen decken und die daher gewissermaßen harmonisiert wurden (z. B. bei der Wiedergabe der Vokale), und dergleichen mehr. Ziel war es also, eine Art literarische Umschrift für das Arabische in seinen im Korpus auftretenden Regionalvarietäten (Ägyptisch, Jemenitisch, Libysch, Marokkanisch und Syrisch) zu entwerfen, mit der mündliche Äußerungen (seien sie regional- oder standardsprachlich realisiert oder andere Eigenheiten aufweisend) authentisch wiedergegeben werden können.
Erweiterung der virtuellen Tastatur im EXMARaLDA Partitur-Editor
Mit Hilfe von Thomas Schmidt konnten die vorgeschlagenen Zeichen zur Erweiterung der DMG-Umschrift ins EXMARaLDA Partitur-Editor implementieren werden (Schmidt 2017). Die ergänzte Belegung für die virtuelle Tastatur ist als DMG+ bezeichnet. Computertechnisch lassen sich die Zeichen in Unicode-basierten Transkriptionseditoren und Textverarbeitungsprogrammen eingeben. Deckt der ausgewählte Schriftsatz die relevanten Unicode-Bereiche ab, dann können Transkriptdateien ohne Weiteres ausgetauscht und weiterverarbeitet werden. Eine Interoperabilität mit derzeit weit verbreiteten Transkriptionstools ist also gegeben.
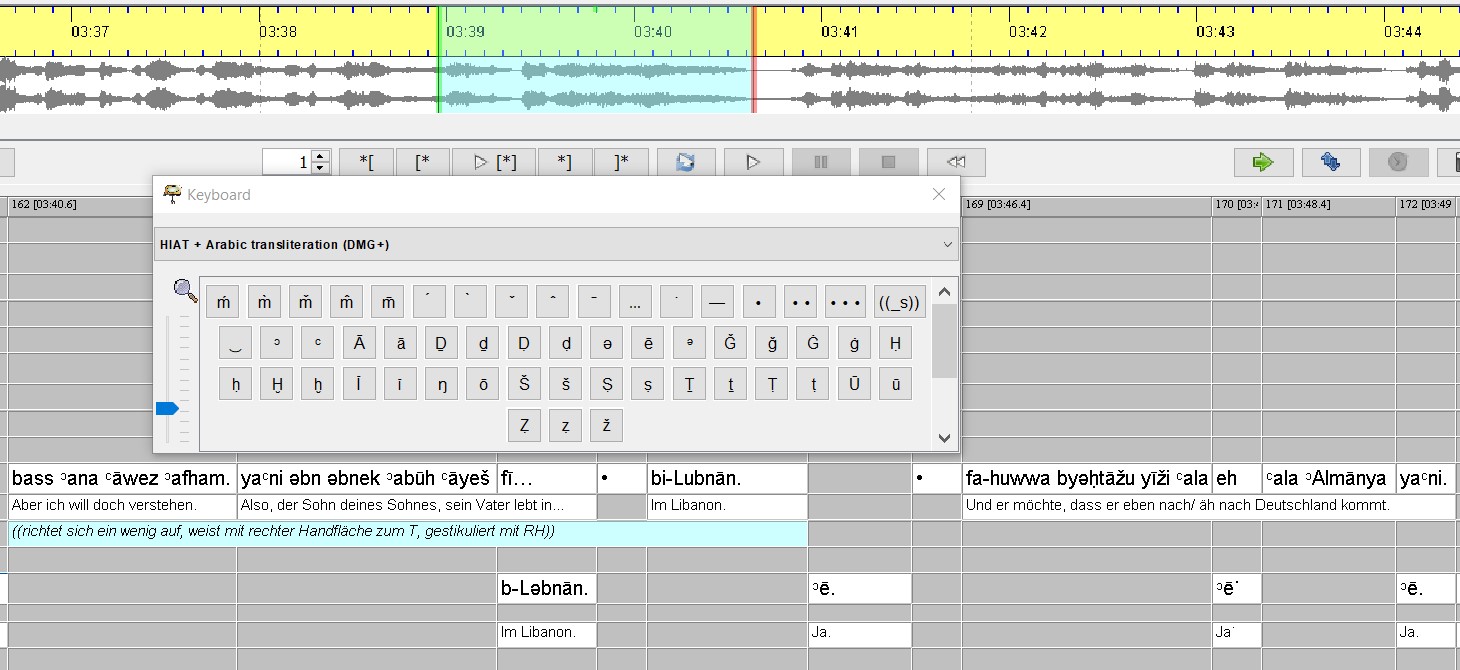
Praktische Handreichung für Transkribent*innen
Die in meiner Arbeit beschriebene Systematik ist nicht erschöpfend, sondern repräsentiert lediglich einen Stand der Dokumentation, der fortschreitet. Sie soll lediglich eine Handreichung für alle sein, die sich Gedanken darüber machen, wie man sich als gesprächsanalytisch arbeitende*r Transkribent*in im Spannungsfeld zwischen einer rein phonetischen, stärker gesprochensprachlichen und einer streng orthografischen, am Schriftbild orientierten Transkription zurecht finden könnte, wobei klar sein sollte, dass eine streng orthografische Vorgehensweise bei einer romanisierten Schreibung des gesprochenen Arabisch mit lateinischen Schriftzeichen ohnehin nicht vertretbar wäre, da das Konzept einer Umschrift bzw. einer phonetisch-orthografischen Transkription in Lateinschrift (anstelle einer graphemgetreuen Transliteration) naturgemäß eine Orientierung an der Lautung vorsieht. Sprachübergreifend könnten unter anderem grundsätzliche Fragen zur Aufbereitung und Zugänglichmachung fremdsprachiger Daten weiter diskutiert werden. Hierzu gehören insbesondere Fragen zum Prozess und zum Produkt der Transkriptübersetzung.
Da sich jede Transkription letzten Endes einem jeweils andersartigen erkenntnistheoretischen Interesse und unterschiedlichen praktischen Erwägungen unterordnen muss, kann ich nicht kategorisch die Verwendung einer lateinbasierten Umschrift fordern. Meine Arbeit möchte sich vielmehr als Impuls zur detaillierten Explikation und zur genaueren Dokumentation von methodischen Vorgehensweisen bei zukünftigen Projekten dieser Art verstanden wissen.
Unidirektionalität im Partiturtranskript: Fallbeispiel aus dem TeDo-Korpus
Geht die Anwendung einer romanisierten Schriftdarstellung des Arabischen nicht mit einem hohen Arbeitsaufwand einher? Gewiss, das tut sie – selbst nach der Systematisierung sowie Verinnerlichung des Vorgehens. Und sie setzt einen spezialisierten Leserkreis voraus, nämlich wissenschaftliche Leser*innen, die sich entweder mit der DMG-Umschrift oder mit anderen wissenschaftlichen Umschriftsystemen auskennen und sich deswegen schnell in die optimierte Systematik einarbeiten können. Aber sie ermöglicht ‒ abgesehen von der (authentischeren) Verschriftbarkeit verbaler Kommunikation und ihrer Analysierbarkeit sowie der verbesserten Suchbarkeit im Korpus ‒ auch Leser*innen ohne Arabisch- bzw. Varietätenkenntnissen einen gewissen Zugang zu den Transkripten, sodass sie selbst nach Schlüsselwörtern suchen und analyseleitende Phänomene identifizieren und quantifizieren können, was die Arbeit in einer mehrsprachigen Forschungsumgebung durchaus erleichtert. Die Frage, welche Leserschaft welche Informationen bräuchte, um einen Transkriptausschnitt als Grundlage für eine Analyse zu nehmen, behandle ich eingehend in der Arbeit.
Der folgende Auszug (Farag 2023: 196) stellt die überarbeitete Fassung des oben angeführten Auszugs aus dem bidirektionalen Transkript dar. Diesen bearbeitete ich so, dass sich die Fläche unidirektional mit einer von links nach rechts laufenden Schrift einrichten ließ. Die eigens optimierte lateinische Umschrift zog ich der arabischen Schrift vor. Um das Potenzial eines romanisierten Vorgehens für darstellungslogische und analytische Zwecke zu verdeutlichen, nahm ich, im Unterschied zum obigen Auszug, analyserelevante nonverbale Aspekte in das Transkriptbeispiel auf und blendete aus Verständnisgründen auch die Übersetzungen ein.

Im Hinblick auf die Visualisierbarkeit des Interaktionsprozesses hat die Verwendung der Umschrift folgende Konsequenzen für die Darstellungslogik:
- eine stimmige Umsetzung zeitlicher Beziehungen in die Transkriptfläche;
- eine korrekte räumliche Zuordnung einzelner Segmente zueinander durch die vereinheitliche Ausrichtung der Schriftzeichen in den einzelnen Spuren;
- eine lineare Transkriptionsrichtung und damit eine Minimierung der Unterbrechungen im Lesefluss, was insbesondere der Rezipierbarkeit der arabischen Einträge zugutekommt, sobald man sich als Leser an die Umschrift gewöhnt hat.
Mit Blick auf die analytischen Vorteile, die ich in meiner Arbeit ausführlicher erörtere, können gewisse Unzulänglichkeiten auf der Ebene der Praktikabilität vorerst in Kauf genommen und im Weiteren (gerne auch kollaborativ) beseitigt werden.
Weiterführende Literatur
Farag, Rahaf (2019): Aspekte der computergestützten Transkription arabisch-deutscher Gesprächsdaten. Gesprächsforschung – Online-Zeitschrift zur verbalen Interaktion (ISSN 1617-1837) Ausgabe 20 (2019), Seite 270-322. [http://www.gespraechsforschung-online.de/fileadmin/dateien/heft2019/px-farag.pdf]
Farag, Rahaf (2019): Conversation-analytic transcription of Arabic-German talk-in-interaction. In: Working Papers in Corpus Linguistics and Digital Technologies – Analyses and methodology, vol. 2. Univ. Szeged: Szeged. 50 S. [https://doi.org/10.14232/wpcl.2019.2]
Farag, Rahaf / Meyer, Bernd (2022): Telefondolmetschen Arabisch-Deutsch: Gesprächstranskription im Spannungsfeld von Mehrsprachigkeit, schriftlichem Standard und Varietätenvielfalt. In: Grawunder, Sven / Schwarze, Cordula (Hg.): Transkription und Annotation gesprochener Sprache und multimodaler Interaktion: Konzepte, Probleme, Lösungen. Tübingen: Narr. S. 213-237.
Farag, Rahaf / Meyer, Bernd (2023): Coordination in telephone-based remote interpreting. In: Interpreting 26.1, 80-113. [https://doi.org/10.1075/intp.00097.far]