

Literary Conventions for the Transcription of Spoken Arabic
Conversation-analytic Approaches to Dealing with Multilingualism, Language Varieties, and Multi-script Notations
Blog post by Rahaf Farag (University of Mainz / Leibniz Institute for the German Language)

Recently, Rahaf Farag’s doctoral dissertation on
Computer-assisted transcription of Arabic-German talk-in-interaction, a methodical contribution to studies on interpreter-mediated encounters
has been published at Peter Lang.
The dissertation is based on a the TIGA corpus (Telephone Interpreting German-Arabic), which can be accessed via the Centre for Sustainable Research Data Management at the University of Hamburg:
Meyer, Bernd / Farag, Rahaf. (2023). Telephone Interpreting German-Arabic (TIGA) / Telefondolmetschen Arabisch-Deutsch (TeDo) (Version 1.0) [Data set].
Computer-assisted transcription of speech is a basic methodical tool for linguistic studies. It is notoriously difficult to reconstruct spoken language by means of writing – even more so when it is embedded in interaction processes that are polylingual and polydialectal. The greater the difference between the writing systems and the less the orthographic standardisation of non-standard varieties, the more difficult the reconstruction. This is also true for the transcription of Arabic-German talk-in-interaction: Arabic script (right-to-left) and Latin script (left-to-right) have opposing writing directions and the established methods to transcribe Arabic data are mostly, first and foremost, concerned with the written language, thus making the data much more difficult to curate. So how can we transcribe and translate Spoken Arabic in a convenient conversation-analytic manner? Which solutions do romanisation systems offer? Under what circumstances can transcription methods and corpus technology meet the needs of interaction-oriented research? How far do current practices support the sustainability and reusability of transcribed data? This book presents self-developed solutions for a systematic approach to Spoken Arabic transcription within polylingual contexts. The data stems from audio and video recordings of interpreter-mediated counselling sessions conducted via the telephone.
Fundamental Challenges of Processing Interactional Data with Arabic Sequences
Transcribing multilingual talk-in-interaction has occupied me for quite some time now, all the while analysing encounters with Arabic-speaking interlocutors and interpreter-mediated conversations, especially in terms of linguistic-communicative practices in Arabic-German telephone-based remote interpreting. Over time, an urgent need of finding solutions for unsolved problems of Arabic transcription has grown. A long journey has led me ultimately to the firm belief that I cannot reasonably meet my specific research requirements without a Latin-based (i.e. romanised) transcription of the Arabic sequences. This was mainly due to the particularities of Arabic scripting (e.g. character set, right-to-left writing system) and the limited technological means to transfer the temporal dimensions of an interaction into the spatial dimensions of a transcript. Attempting to merge opposing directionalities of Arabic and German scripts into one graphically organised transcript causes graphical distortions, thus affecting its readability, and impedes, or even prevents, the analysis of the reconstructed data, regarding communicative dynamics and other temporal aspects.
Leftward Directionality of the Arabic Script vs. Rightward Directionality of German Script
One major obstacle when curating Arabic (monolingual or multilingual) data is the rightward arrangement of Arabic script. The available software tools, including EXMARaLDA, were developed for left-to-right writing systems. Hence, their user interfaces do not support any other typing direction except for the horizontal, right-to-left one. Accordingly, transcribers have to follow the predefined structure of the progressive (score) interface, such as the rightward display of the linearly unfolding events along a timeline and the vertical arrangement for simultaneous activities and acoustic or visual occurrences. Every tier represents a course of action and their annotations. Anchoring events and otherwise parallel items to the ongoing timeline enables a synchronisation of ongoing multimodal activities. In principle, the interface supports a rightward writing within the fixed units (tiers, segments). To examine this, I used data from my project on telephone-based interpreting as presented in the following example (Farag 2023: 193).

K3 is a Syrian client who lives in a small town in southern Germany. He has been trying in vain to bring his family to Germany ever since he was granted subsidiary protection. To seek counsel at a local authority, he had to rely on the interpreting, which was performed consecutively via the telephone by a remotely located interpreter (TD2). In this excerpt, the client recounts his experiences during the asylum procedures and highlights the great difficulties in reuniting with his family. To lay the focus on utterances’ arrangement and display format, I did not include translations and further annotations. The blue arrows indicate the reading direction.
As can be seen from this excerpt, EXMARaLDA Partitur-Editor allows horizontal leftward writing within a segment and an output of bidirectional transcripts. However, the representation of the interpreter’s and the client’s simultaneous utterances is adversely affected by the bidirectionality of the interface and the tridirectionality of the reading direction (left-right, top-bottom, right-left). The reading flow is constantly interrupted. Arabic segments are arranged along the leftward interface and can be read from right towards left, irrespective of the opposed temporal progression. One would start at the right side, stop at its left end, and then avert their eyes to the next segment on their right to continue reading, and so forth ‒ whether an utterance ends at the end of a segment or not. Turn transitions and points at which an interlocutor could claim the turn (transition relevance places) are misaligned ‒ at least from the perspective of a reader who understands Arabic. So the software would, by way of example, record a pause or a closing of an utterance at the beginning of an utterance or a segment, not at its end. All reading falters when irregularities such as interruptions and (longer) simultaneous sequences (overlapping talk, turn claims) occur. Eventually, references, sequences, and entire courses of action become incomprehensible. Beside twists in the alignment of the events, further displacements and visual distortions (incl. text display) occur after compressing the transcript into an A4 page format and adapting score sections to its page breaks. The spatial disarrangement is evident in the segments 168, 169-170 und 174-178. Hence, a bidirectional display, as shown above, is not eligible as a working basis.
Since every attempt to merge both writing systems into the transcript failed to serve the purposes in question, the next questions to be examined were how and to which extent could a romanised transcription of Arabic remedy the aforementioned defictis. For transcription-technical, analytic, and publication-related reasons I decided in favour of a mono-script, Latin-based notation. Then again, the suitability of various romanisation systems had still to be determined. With every step and every inquiry I became more and more aware that I have entered an uncharted methodical territory, with fascinating scopes, yet highly complex requirements. This, in turn, stirred up discussions on controversial approaches, also revealing the blind spots and problematic habits in certain research practices.
Customised System for a Conversation-analytic Transcription of Spoken Arabic-in-Interaction
To date, the transcription of Spoken Arabic, in terms of its reconstruction by means of writing and its transfer from an oral to a written medium, has barely been systemised. It is hard to capture less standardised vernaculars, varieties, and spoken language features, such as interjections, hesitation markers, and non-lexical backchannels. They have not received any notable attention outside the fields of Arabic dialectology and socio-linguistics. Well-established German- and English-based romanisation systems belong mostly to philological and historical or rather historical-geographical contributions. They have caught on in the fields of library and information management, lexicography, and geography, cartography in particular, aside from the world of science. Being concerned with the written language, they are guided by standard orthography and pronunciation, hence they call normatively for uniformity and consistency. Therefore, they have not proven to be easily applicable when conserving natural and spontaneous speech.
Empirical research on Arabic data from talk-in-interaction does not look back on a long-standing tradition, beyond the fields of Arabic studies and dialectology, computational linguistics, socio-linguistics, acquisition studies or the like. This might be the reason why the German- and English-based scientific and research world suffers from a scarcity of orthographic transcription systems for Arabic, romanisation systems to be exact, that are (first and foremost) designed to tap and understand language-in-daily-life or -in-interaction. One can hardly find interaction corpora or linguistic resources that have been made or would be accessible for common benefit. Data are usually published for illustrative purposes in form of excerpts. Numerous cases were lacking transparency and (critical) methodical reflection on how they were collected and curated. So they did not offer any viable solutions.
The system I decided to adopt builds on the well-established guidelines of the German Oriental Society, known as the DMG romanisation, which date from 1935 (Brockelmann et al.). It holds on to the features of the spoken daily languages, unlike what was originally stipulated by the DMG and similar guidelines, while heeding the principles of readability, comprehensibility, and consistency. Guaranteeing authentic rendering in sense of a close, but purposeful proximity to the raw data and ensuring its analysability, reusability, and practicability (e.g. corpus searchability) remains a perpetual juggle.
The DMG system provides the basic, processable character set which allows a unidirectional transcription. It promotes a rather clear relationship between graphemes and phonemes in the Latin script, thus reducing ambiguities and misinterpretations, compared to non-scientific, non-systemised romanisation systems.
Still, I had to modify and expand its character set in order to reach a phonologically oriented, yet orthographic representation of non-standard, spoken language phenomena as an attempt to develop literary conventions (Ger. literarische Umschrift). Steering a middle course between a rigid reproduction of phonetic realisations and an orthographic normalisation has proven to be essential for integrating the diverse varieties spoken by the participants (Egyptian, Libyan, Moroccan, Syrian, and Yemeni Arabic) into the data corpus. Making each largely distinguishable facilitates an investigation of interaction dynamics, (one-sided or mutual) accommodation and adaptation processes as well as other forms of code mixing performed to ensure understanding and build rapport with one another (cf. Farag/Meyer 2022, 2023).
I created a guideline documenting my decisions and suggestions for the transcription of verbal actions (Arabic utterances). Both characters’ inventory and these guidelines strive to meet conversation-analytic postulates, like reaching a broadly manageable and efficient transcription process, by making the romanisation more accessible, teachable, and applicable for transcribers and corpus users. Another goal was to address issues that are fundamental for similar approaches and to indicate others that vary depending on one’s individual demands, also offering sufficient leeway for determining when disregarding (lexical-morphological or phonetic-phonological) variations and interactional phenomena would still be in line in line with interaction-oriented transcription principles and when departing from the DMG or orthographical conventions (e.g. resorting to dialectological and sociolinguistic work) while developing one’s own solutions would be essential.
When I developed these guidelines, it was important for me to ensure their suitability for the transcripts’ score layout and for their conformity with the Conventions of Semi-Interpretive Working Transcription (Ger. HIAT; cf. Rehbein et al. 2004). Nevertheless, the system is compatible with other reconstructive approaches to spoken language-in-interaction and to other display formats and transcription conventions.
A Modified Virtual Keyboard in the EXMARaLDA Partitur-Editor
Thomas Schmidt stored the characters that I proposed to extend and enhance the DMG characters’ set in EXMARaLDA Partitur Editor (Schmidt 2017). The virtual keyboard facilitates entering special (diacritical and phonological) characters that are not be available on a normal keyboard. The new the add-ons are designated as DMG+. All characters are compatible with Unicode-based transcription tools and text editors. They allow creating a machine-processable content. Transcript files can be easily exchanged with other tools as long as the chosen font has a wide Unicode coverage.
Practical Guide for Transcribers
The principles I describe in my book are neither resolved nor exhaustive, but merely represent a current, yet progressive status of documentation and exemplary references for decision-making. The book offers a guide for transcribers who are wondering how to mediate between an extensive phonetic reconstruction of spoken language data (e.g. due to one’s commitment for scientific precision) and a rigorous orthographic levelling for the sake of a readable, efficient (regarding time investment and workload), and yet purposeful output. Either way, a rigorous orthographic approach to a Latin transcription of Spoken Arabic would not be tenable, since the concept of transcription is concerned with the (reconstructive) transfer of data from an oral to a written medium ‒ using Latin characters for Arabic, whose phonetic elements (e.g. vowels, geminations) have a restricted presence in its script per se. Unlike transliteration, its aim is not to transform one typography into another typography in terms of a grapheme-to-grapheme conversion of scripts, maintaining its unambiguity and reversibility ‒ regardless of the language. What I propose here is therefore a phonetic- or phonological-orthographic transcription from an articulation of one language (source) into the orthography of another language (target).
I cannot categorically recommend a romanised transcription of Arabic, for every transcription is subjected to different epistemological interests and practical considerations. Rather, I would like my work to be perceived as an impetus for future projects and similar endeavours to elucidate and document methodical avenues in greater detail.
As for cross-linguistic topics and common findings, it is necessary to discuss fundamental and ethical questions regarding the processing and dissemination of foreign language data, like transcript translation (production, status, purpose, display, etc.).
Unidirectional Alignment in Score Transcripts: An Example from the TIGA Corpus
Isn’t Latin-based writing of Arabic quite time-consuming? It is, indeed, despite all systematisation efforts to enable a (precise and authentic) transcription of verbal communication and to facilitate its (corpus-based) analysability. As regards readability, producing romanised transcripts narrows the readership to (linguistic) scholars who are familiar with the DMG system or other scientific systems so that they can catch up easily with modified guidelines and self-developed solutions. On the other hand, non-Arabic and non-dialect readers get a little access to the transcripts. Being literate in the Latin alphabet they find their way around better, thus formulating queries, identifying keywords, quantifying candidate or relevant discursive phenomena, etc. This has proven advantageous for a multilingual research environment. Another question the book addresses in this context is naturally which level of detail is necessary to take a transcript as a basis for analyses.
The following excerpt (Farag 2023: 196) is the revised version of the bidirectional excerpt above. I treated it according to the tailored system so as to reorder the interface into a one-directional, left-to-right flow, replacing the Arabic script by its romanised form. Unlike the previous excerpt, this sample contains the translations of the verbal utterances and the transcription of selected non-verbal activities, in addition to the para-verbal ones, in order to exemplify the potential of a romanised approach for interaction’s visualisation and analysability.
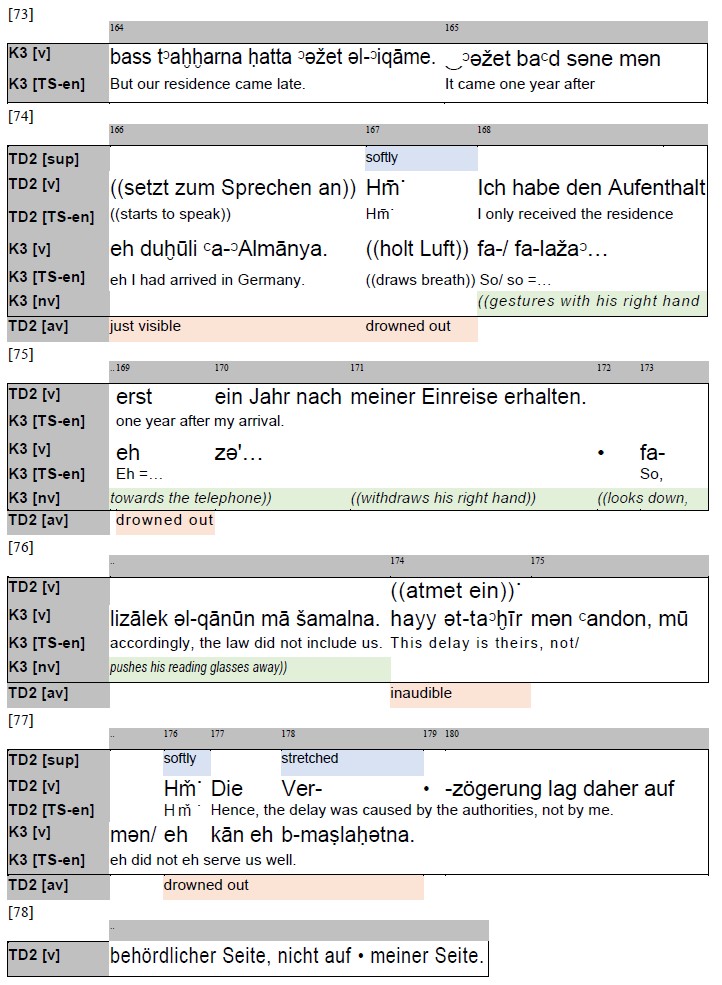
This sample helps to understand the logic behind preferring this design format over the one above. Using a Latin script effects data visualisation as follows:
- an exact alignment of temporal relationships within the progressive transcription interface;
- a correct spatial arrangement of the segments;
- a linear and uniform flow of transcription, thus minimising interruptions in the reading flow, but mainly serving the readability and comprehensibility of the Arabic parts, provided one becomes accustomed to the romanisation system.
In view of the possibilities offered by such an approach and other analytic benefits that are revealed in my book, one needs to put up with its few shortcomings, like a reduced practicality ‒ at least for the time being. I would like to diminish them further on ‒ collaboratively where required.
Further References
Farag, Rahaf (2019): Conversation-analytic transcription of Arabic-German talk-in-interaction. In: Working Papers in Corpus Linguistics and Digital Technologies – Analyses and methodology, vol. 2. Univ. Szeged: Szeged. 50 S. [https://doi.org/10.14232/wpcl.2019.2]
Farag, Rahaf / Meyer, Bernd (2023): Coordination in telephone-based remote interpreting. In: Interpreting 26.1, 80-113. [https://doi.org/10.1075/intp.00097.far]