Training Corpus of Spoken Slovenian ROG 1.0
This week, the Mezzanine project published version 1.0 of the Training Corpus of Spoken Slovenian – ROG 1.0. The corpus is available via the CLARIN.SI repository: https://www.clarin.si/repository/xmlui/handle/11356/1992.
ROG 1.0 is the main resource for the Slovenian language to train and evaluate technologies aimed at processing speech or speech transcripts, such as part-of-speech taggers, parsers, prosodic unit segmenters, disfluency identifiers, dialogue act classifiers etc. It is also suitable for performing speech-related research.
ROG 1.0 consists of two parts:
1. ROG-SST, which includes selected Gos 2.1 (http://hdl.handle.net/11356/1863) transcriptions with:
– manually assigned lemmas and morphosyntactic tags according to the MULTEXT-East annotation scheme (https://nl.ijs.si/ME/V6/msd/html/msd-sl.html),
– manual annotations according to the Universal Dependencies annotation scheme (i.e. part-of-speech categories, morphological features and syntactic dependencies)
In total, ROG-SST spans 76,341 words and 6,108 sentences.
2. ROG-Art, which includes:
– all the annotation layers from the ROG-SST
– prosodic units annotations
– disfluencies annotation – dialogue acts annotation
ROG-Art consists of 39,001 words in 1,969 sentences.
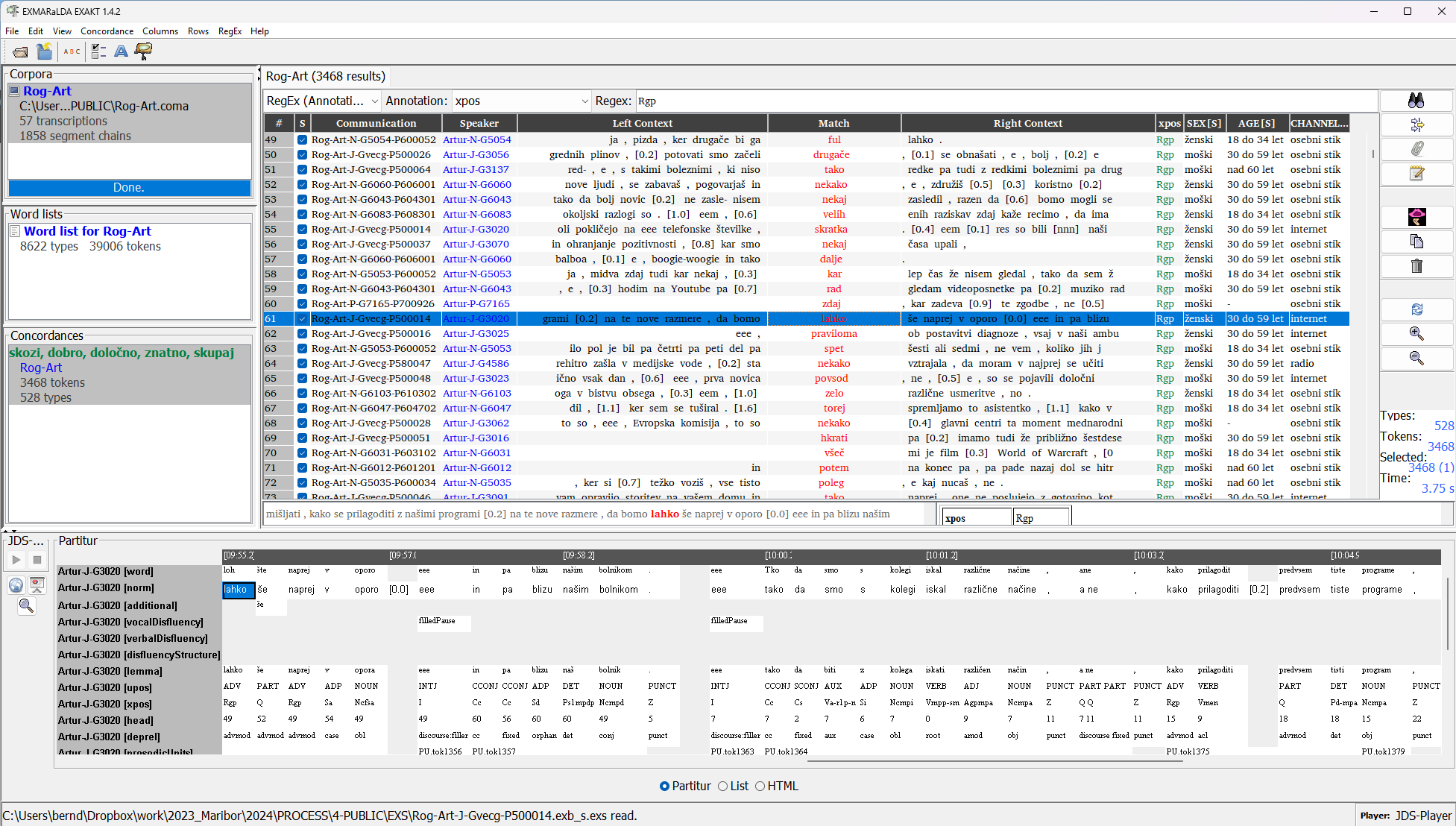
ROG-Art was annotated with the EXMARaLDA Partitur-Editor and is available for download as an EXMARaLDA corpus:
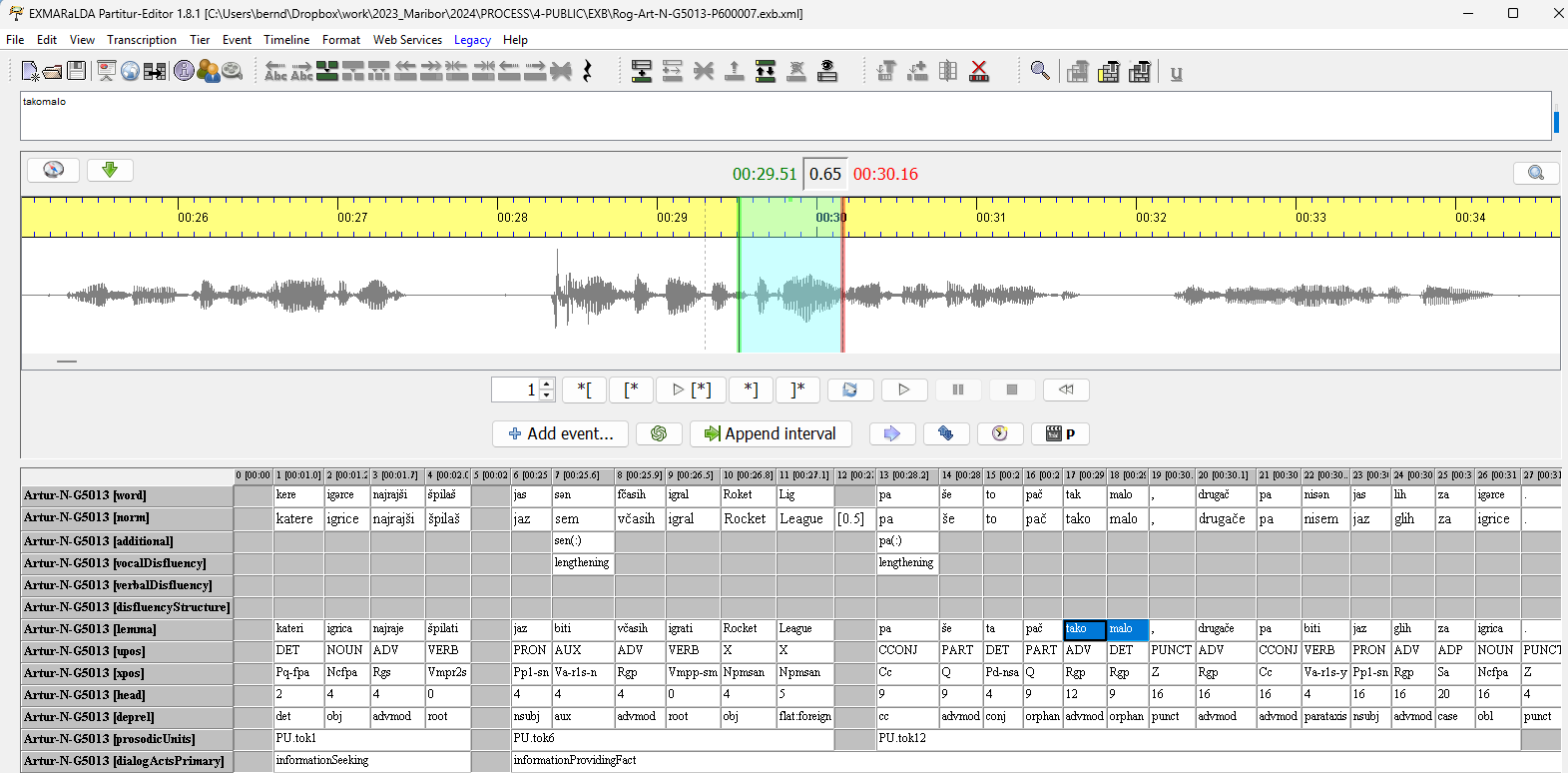
All annotation layers as well as various metadata fields on recordings and speakers can be queried and analysed with EXAKT.