
EXMARaLDA-powered corpora of endangered languages of Siberia: INEL project
By Elena Lazarenko and Alexandre Arkhipov
A collection of corpora encompassing several highly endangered languages of Northern Eurasia by the long-term Academy project INEL (2016–2033) is hosted by the Centre for Sustainable Research Data Management at the University of Hamburg. Our latest releases (2024–2025) represent the Uralic languages Enets, Nenets and Nganasan from the Far North as well as Tavda Mansi, and the Tungusic language Evenki.
The corpora can be downloaded to work offline under the CC BY-NC-SA 4.0 license as well as accessed via a web search interface.
The project is funded by the Academy of Sciences in Hamburg within the Academiesʼ Programme jointly financed by German federal and state governments.
Research Goals
Since 2016, the long-term Academy project INEL (“Grammatical Descriptions, Corpora, and Language Technology for Indigenous Northern Eurasian Languages”) has been delivering deeply annotated corpora and accompanying linguistic resources of selected highly endangered languages and varieties.
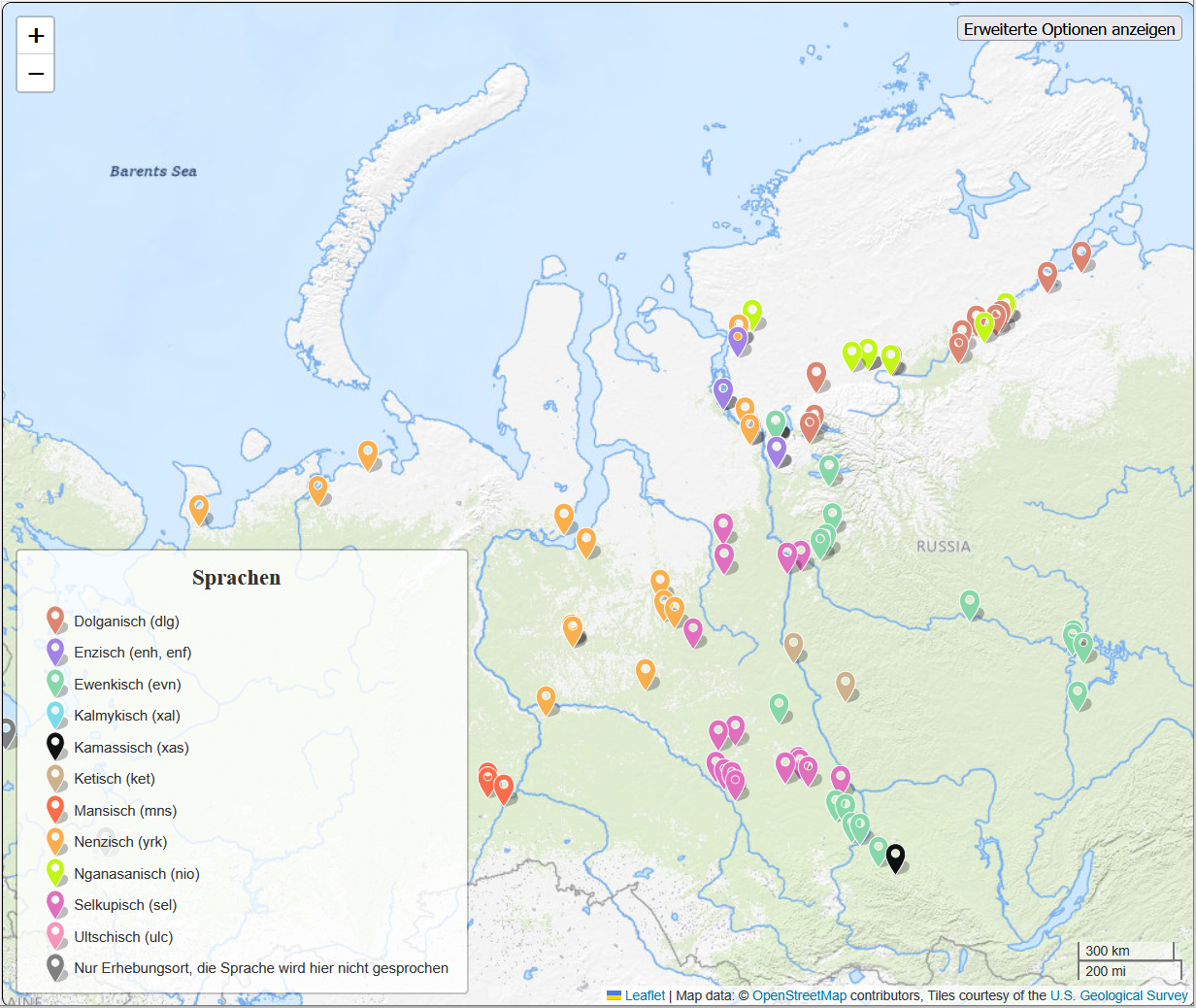
The territories of the project research interest are home to many indigenous languages. Most of them are seriously endangered, some spoken by no more than several dozen people, and some altogether extinct. The INEL project aims to collect, digitize, linguistically annotate, and make their materials permanently available in the form of language corpora.
In contrast to many recent language documentation projects, most of our data had been collected earlier – some of them in the last decade or two, while some others are more than a century old. One of the challenges is to bring the data of different times and origins into a unified digital format which enables consistent linguistic analysis.
Methods
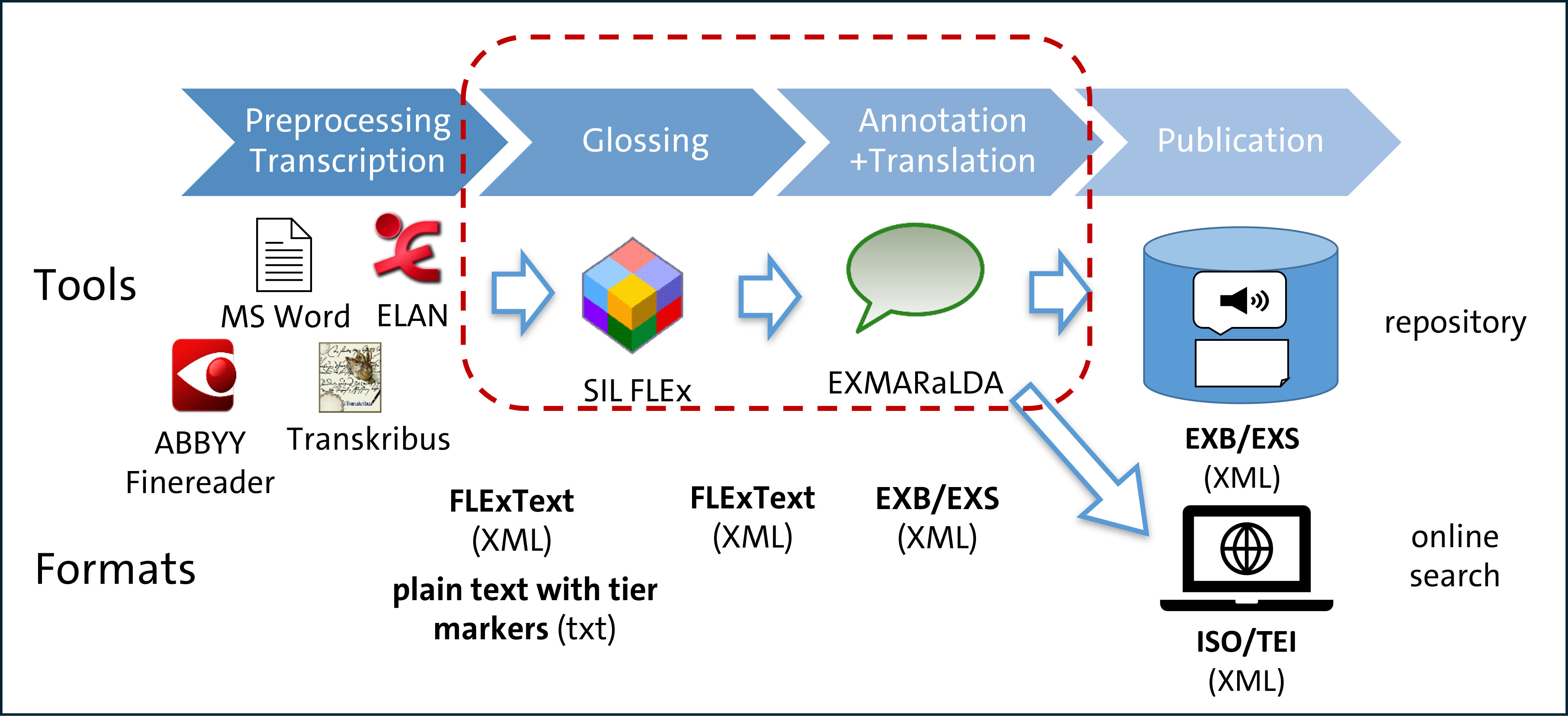
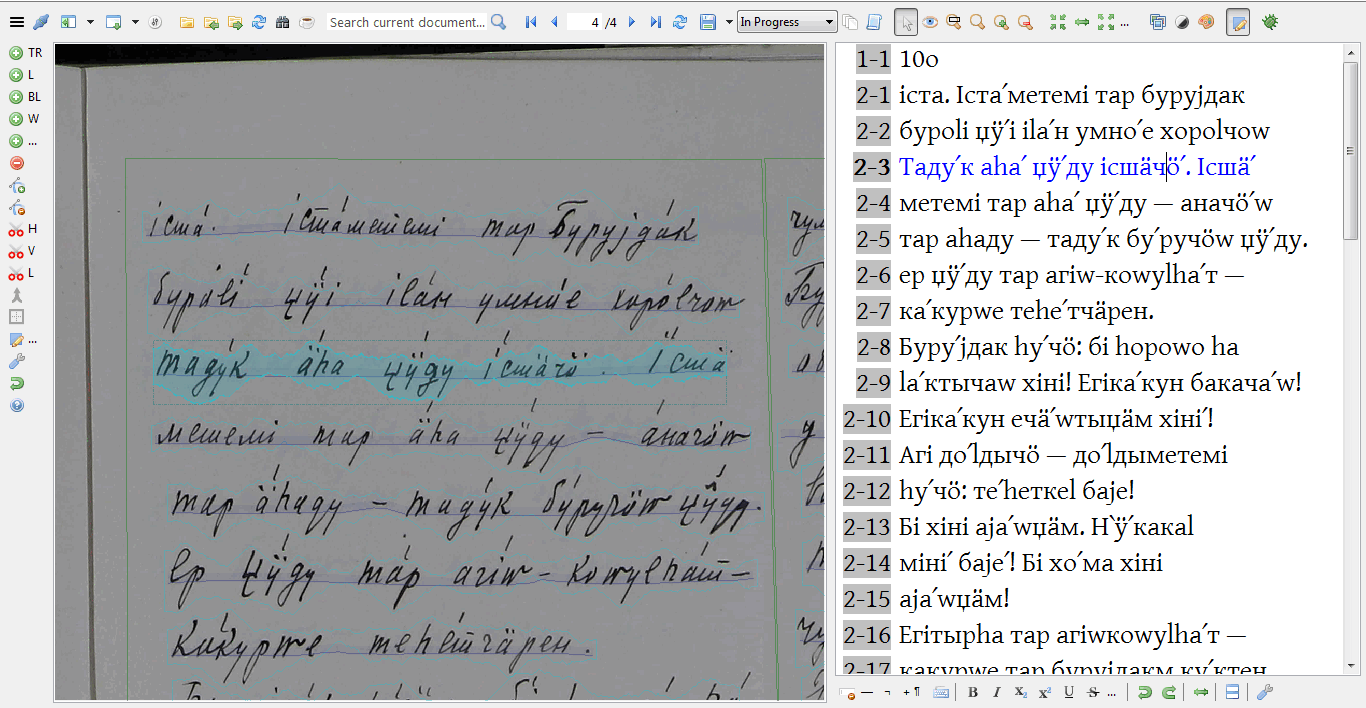
| We work with various formats of original (primary) data, such as books, audio recordings and manuscripts. They all require tailored preprocessing workflows in order to be transformed into XML transcripts which then undergo grammatical analysis in SIL FLEx. At this stage, each wordform is morphologically analyzed to obtain an interlinear glossed text (IGT) which is a standard representation in linguistic typology and related disciplines. |
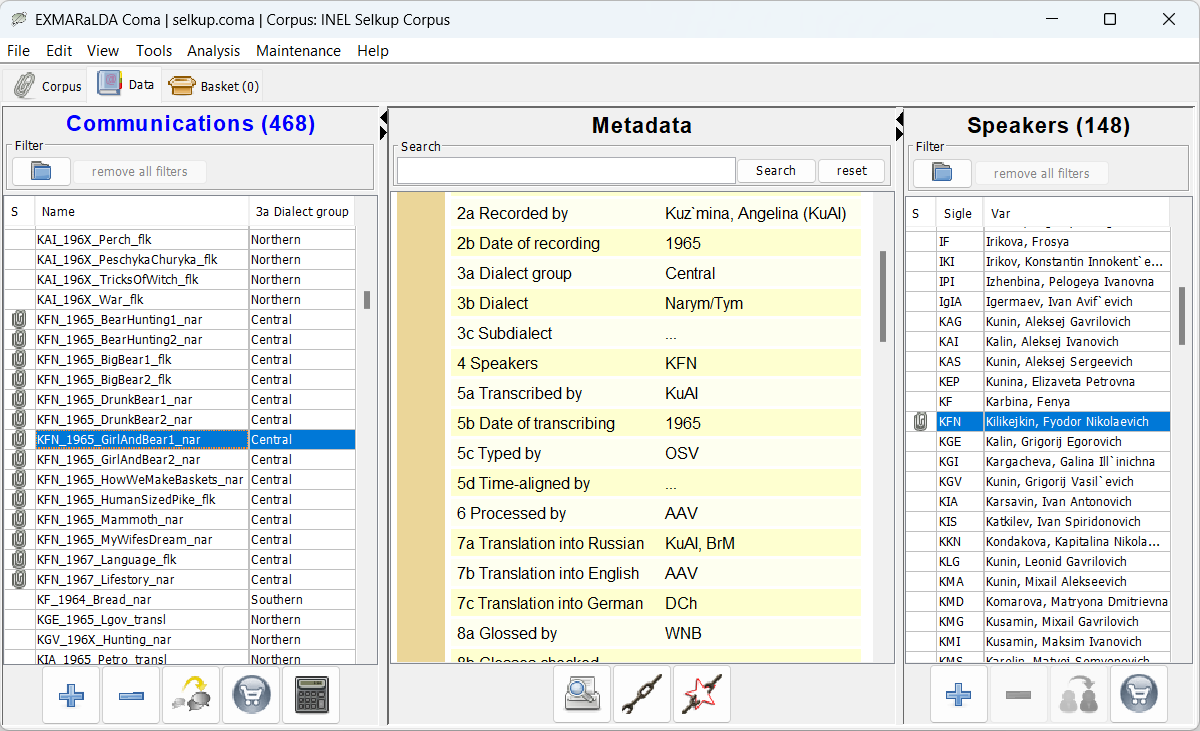
At the next stage, the corpus is built using the EXMARaLDA package: we create the main metadata file, export the transcripts in the EXMARaLDA basic transcription format and link them together.
The Coma file includes a wealth of information on when and where the data were recorded, who contributed to the data collection, annotation and curation, as well as biographical and sociolinguistic information about the speakers wherever available.
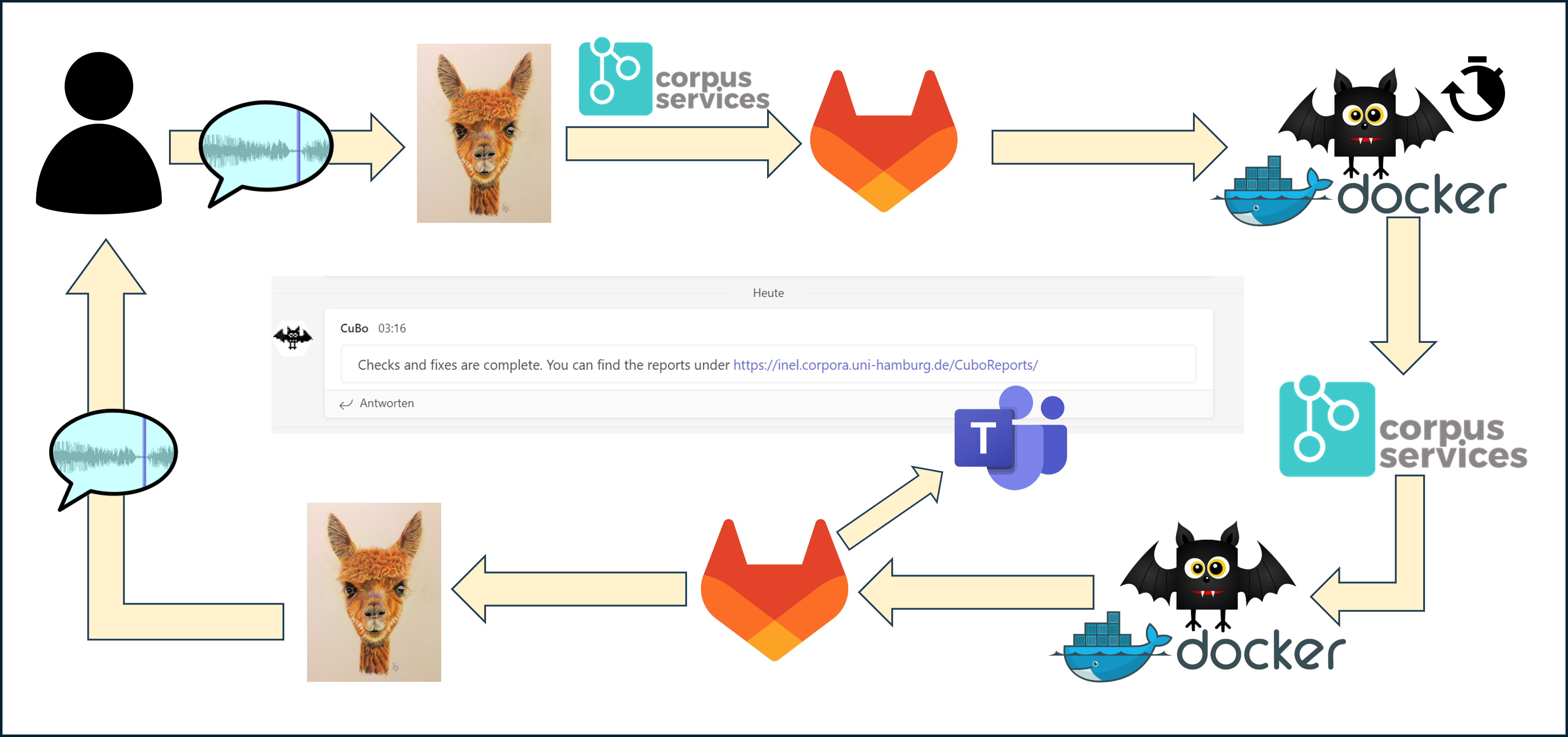
After the transfer into the EXMARaLDA formats, the data are further annotated and extensively curated, both manually by the project members and automatically. This includes automatic checks and fixes using the project-specific Corpus Services framework that leverages EXMARaLDA codebase (Hedeland/Ferger 2020, Riaposov/Lazarenko 2024).
We add further layers of analysis using the Partitur Editor including annotation of syntactic functions and semantic roles, borrowings and code-switching (Arkhipov 2020). The texts are obligatorily translated into English and Russian, most often also into German. The original transcriptions and translations as provided in the existing publications are also included. Taken together, we arrive at more than 20 annotation layers per speaker. Besides, the event structure is determined by segmentation into words and sentences, of which only sentences are time-aligned. This complex structure has required special adaptations in EXMARaLDA, including e.g. the ability to copy&paste multiple annotation cells together (e.g. a sentence with all its words and annotation tiers).
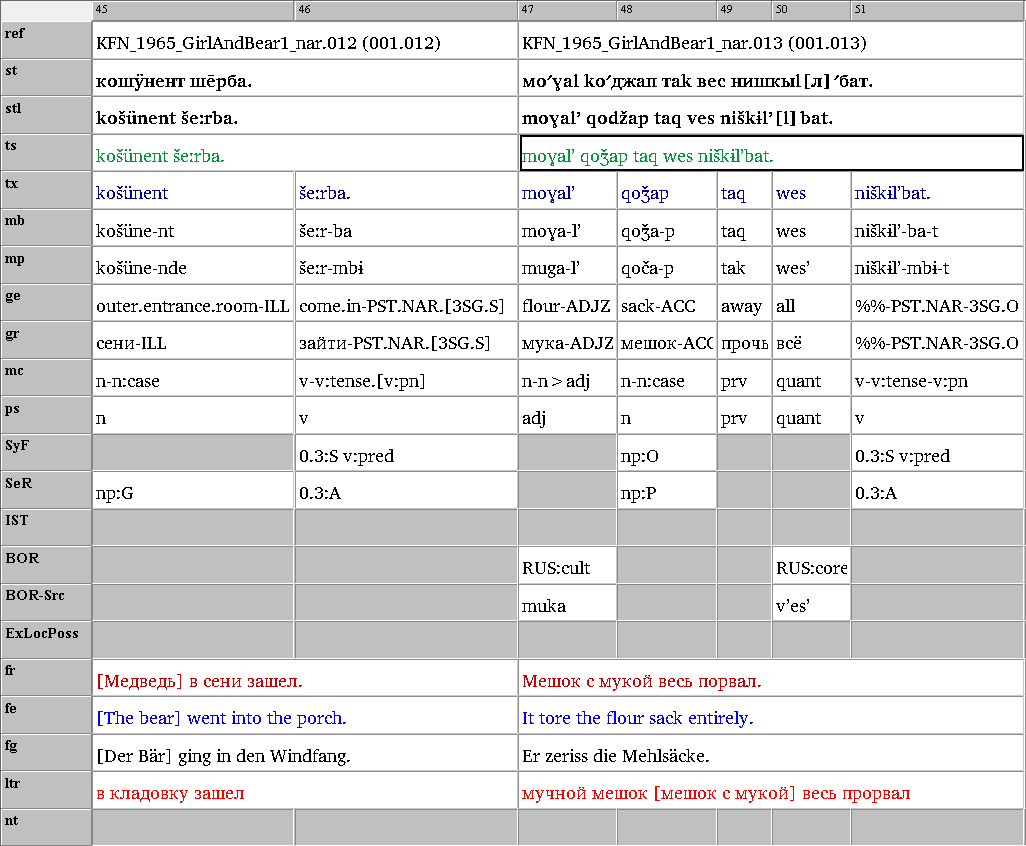
A new event-based segmentation algorithm developed specifically for the INEL project allows a streamlined error-free export into the ISO/TEI format which is provided with the corpora and used in particular by the Tsakorpus online search platform. Each corpus is published as a downloadable archive that contains all the files necessary to work with the data offline using the EXMARaLDA tools including the main metadata file, basic and segmented transcriptions, further export formats (ISO/TEI and ELAN) and optionally the source data in form of audio recordings and/or PDF scans.
References
- Arkhipov, A. 2020. INEL Corpora General Transcription and Annotation Principles. Working Papers in Corpus Linguistics and Digital Technologies: Analyses and Methodology. Vol. 5. Szeged; Hamburg. https://doi.org/10.14232/wpcl.2020.3
- Hedeland, H. & Ferger, A. 2020. Towards Continuous Quality Control for Spoken Language Corpora. International Journal for Digital Curation, 15(1). https://doi.org/10.2218/ijdc.v15i1.601
- Riaposov, A. and E. Lazarenko. 2024. Corpus Services: A Framework to Curate XML Corpus Data. In Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC—COLING 2024), pages 4030–4035, Torino, Italia. ELRA and ICCL. https://aclanthology.org/2024.lrec-main.358/
Subprojects and Corpora
Dolgan
Däbritz, Chris Lasse; Kudryakova, Nina; Stapert, Eugénie. 2022. INEL Dolgan Corpus. Version 2.0. Publication date 2022-11-30. https://hdl.handle.net/11022/0000-0007-F9A7-4.
Online search: https://inel.corpora.uni-hamburg.de/DolganCorpus/search
Dolgan belongs to the North Siberian group of north-eastern Turkic languages and is spoken by about 1000 people on the Taimyr Peninsula and in neighbouring areas in the Far North of Siberia. The data in the INEL Dolgan Corpus 2.0 originate from published texts as well as fieldwork recordings and recordings obtained from the Taymyr House of Folk Art.
- Archival part: 37 audio recordings /
Total duration of audio: 10 hours 00 min - Glossed (searchable) part: 136 texts, 14,193 sentences, 97,625 tokens /
Total duration of audio: 14 hours 15 min
Enets
Shluinsky, Andrey; Khanina, Olesya; Wagner-Nagy, Beáta. 2024. INEL Enets Corpus. Version 1.0. Publication date 2024-11-30. https://hdl.handle.net/11022/0000-0007-FE1D-C.
Online search: https://inel.corpora.uni-hamburg.de/EnetsCorpus/search
The INEL Enets corpus 1.0 includes texts recorded between 1962–2017 in Tundra and Forest Enets (< Samoyedic < Uralic). The sources of the data include various published and legacy audio recordings as well as published texts and legacy manuscripts. Video recordings are also included into the corpus where available.

- Forest Enets: 541 texts, 41,396 sentences, 173,379 tokens
- Tundra Enets: 137 texts, 12,737 sentences, 45,331 tokens
- Total: 678 texts, 54,133 sentences, 218,710 tokens
- Total duration of audio: 43 hours 26 min
Evenki
Däbritz, Chris Lasse; Gusev, Valentin; Stoynova, Natalia. 2024. INEL Evenki Corpus. Version 2.0. Publication date 2024-12-31. Archived at Universität Hamburg. https://hdl.handle.net/11022/0000-0007-FE38-D.
Online search: https://inel.corpora.uni-hamburg.de/EvenkiCorpus/search
Evenki is a Tungusic language whose speakers are dispersed throughout Siberia and the Far East. The INEL Evenki Corpus 2.0 covers Northern (Taimyr, Khantayskoe Ozero, Ilimpi, Yerbogachyon) and Southern (Sym, Barhahan, and to a smaller extent Stony Tunguska and Nepa) Evenki dialects. These are the dialects which are or were in contact with other languages included in the INEL project, first and foremost Dolgan and Selkup. The corpus contains texts from different sources that date back to as early as 1900s/1910s.
- 612 texts, 19,931 sentences, 93,264 tokens
- Total duration of audio: 3 hours 58 min (69 texts)
Kamas
Gusev, Valentin; Klooster, Tiina; Wagner-Nagy, Beáta. 2023. “INEL Kamas Corpus.” Version 2.0. Publication date 2023-12-31. http://hdl.handle.net/11022/0000-0007-FC25-4.
Online search: https://inel.corpora.uni-hamburg.de/KamasCorpus/search
Kamas is an extinct Samoyedic (< Uralic) language spoken in Southern Siberia. The INEL Kamas corpus 2.0 consists of two parts: folklore texts collected by Kai Donner in 1912–1914, and transcribed audio recordings of the last speaker of Kamas, Klavdiya Plotnikova, made between 1964 and 1970.
- Total: 154 texts, 13,876 sentences, 63,810 tokens
- Total duration of audio: ca. 14 hours
Nenets
Budzisch, Josefina; Wagner-Nagy, Beáta. 2024. INEL Nenets Corpus. Version 1.0. Publication date 2024-12-31. https://hdl.handle.net/11022/0000-0007-FE37-E.
Online search: https://inel.corpora.uni-hamburg.de/NenetsCorpus/search
The INEL Nenets Corpus 1.0 includes texts recorded between 1940–2011 in both Nenets lects – Forest Nenets and Tundra Nenets (< Samoyedic < Uralic). The majority of texts in this corpus originate from published works. Audio recording is also provided for one text.
- Forest Nenets: 80 texts, 3,709 sentences, 23,597 tokens
- Tundra Nenets: 56 texts, 6,545 sentences, 37,681 tokens
- Total: 136 texts, 10,254 sentences, 61,278 tokens
- Total duration of audio: 45 min
Nganasan
Brykina, Maria; Gusev, Valentin; Szeverényi, Sándor; Wagner-Nagy, Beáta. INEL Nganasan Corpus. Version 1.0. Publication date 2025-05-02. https://hdl.handle.net/11022/0000-0007-FE63-C. Online search: https://inel.corpora.uni-hamburg.de/NganasanCorpus/search
Nganasan (< Samoyedic < Uralic) is the northernmost language of Eurasia. The INEL Nganasan corpus is largely based on the Nganasan Spoken Language Corpus (v0.2, 2018) adapted to the INEL standards and supplemented with new texts. The glossed (searchable) part of the corpus includes texts provided with source media files (whenever available) and annotated transcripts. The archival part of the corpus contains non-glossed texts, represented either by audio recordings (optionally – with preliminary transcriptions) or scanned pages of the manuscripts or publications.
- Glossed (searchable) part: 236 texts, 34,872 sentences, 221,747 tokens
Total duration of audio: 49 hours 53 min - Archival part: 98 hours of audio material (210 texts) and 30 manuscripts

Selkup
Brykina, Maria; Orlova, Svetlana; Wagner-Nagy, Beáta. 2021. INEL Selkup Corpus. Version 2.0. Publication date 2021-12-31. https://hdl.handle.net/11022/0000-0007-F4D9-1.
Online search: https://inel.corpora.uni-hamburg.de/SelkupCorpus/search
The INEL Selkup corpus 2.0 is composed of texts from the archive of Angelina Ivanovna Kuzmina (1924–2002), who gathered a large amount of material on Selkup (< Samoyedic < Uralic) in almost all the regions where the Selkup people lived between 1962–1977. Most texts in the corpus originate from the handwritten part of the archive, the others come from sound recordings made by A.I. Kuzmina, transcribed and translated within the INEL project.
The archival part of the corpus contains texts which have not been glossed, but some of them have preliminary transcriptions.

- Glossed (searchable) part: 352 texts, 14,509 sentences, 81,498 tokens
Total duration of audio: 3 hours 34 min - Archival part: 3 manuscripts and 40 audio recordings
Total duration of audio: 7 hours 6 min
Tavda Mansi
Sipőcz, Katalin & Wagner-Nagy, Beáta. 2025. INEL Tavda Mansi Corpus. Version 1.0. Publication date 2025-05-15. https://hdl.handle.net/11022/0000-0007-FE69-6.
Online search: https://inel.corpora.uni-hamburg.de/TavdaMansiCorpus/search
The analysis of materials from the now extinct Tavda variety of Mansi (< Ob-Ugric < Uralic) has already been conducted by Norbert Szilágyi, but he did not produce a corpus that could be searched and evaluated electronically. In the material published in the INEL corpus, the analyses differ significantly from Szilágyi’s analysis. For the sake of comparison, the texts analyzed by Szilágyi are appended to the corpus, and the Hungarian translations he provided have been retained, but some places have been corrected.
- Total: 29 texts, 2,042 sentences, 11,879 tokens