

User story: ExmaraldaR – Processing (Annotated) Transcripts in R
The R package ExmaraldaR is intended to allow easy processing of (annotated) transcripts R (R Core Team 2020). R is a free platform for statistical analysis, data preparation and also Natural Language Processing. It thus offers numerous options that are also interesting for the study of spoken language. With the package, one or more annotated transcriptions (*.exb) can be read in. Annotated transcripts then result in a table object that can be used for further work (see Figure 1).
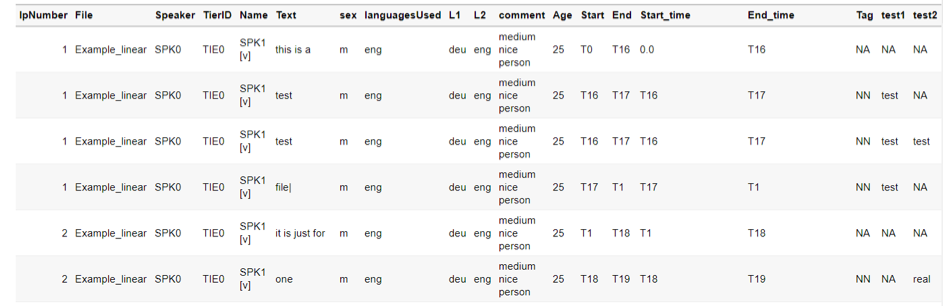
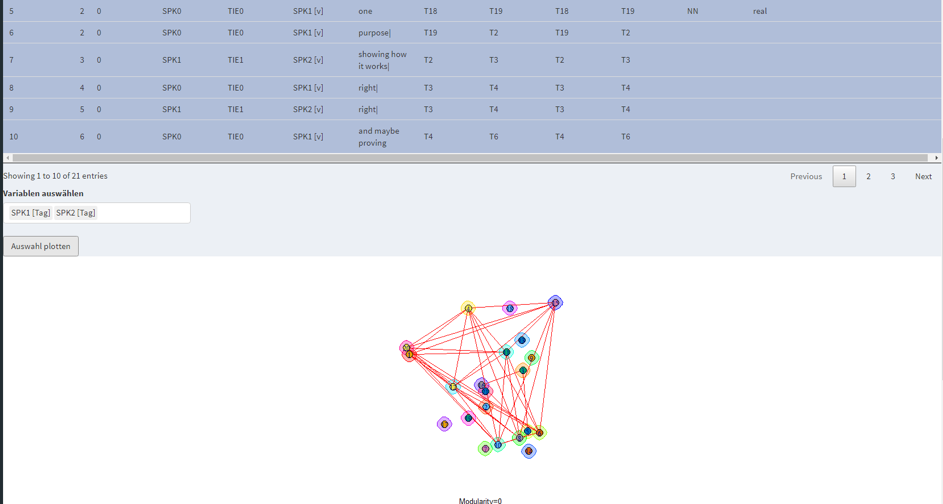
The table contains a consecutive IP numbering based on the GAT2 conventions (Selting et al. 2009), the speaker sigle, the ID of the tier, the speaker name, the transcription text, the metadata of the speaker table (optional), timestamp of the event and the annotations. The annotations are directly assigned to the transcribed text. Different annotation formats are possible (complex annotation tags that are separated or multiple annotation tracks). Descriptive tiers can also be integrated. In future, it should also be possible to transfer changes made in R or to the table (e.g. after an export to Excel) directly back into the underlying files to simplify post-processing. Templates for integration into R-Shiny applications can be requested if required (see Fig. 2). If you have any questions or would like to test the package, please contact timo.schuermann@uni-meunster.de.
A beta version, which is under constant development, can be found here:
https://github.com/TimoSchuer/ExmaraldaR
References
R Core Team (2020): R. A Language and Environment for Statistical Computing. Version 3.6.0: R Foundation for Statistical Computing. Online verfügbar unter https://www.R-project.org.
Selting, Margret; Auer, Peter; Barth-Weingarten, D.; Bergmann, Jörg; Bergmann, Pia; Birkner, Karin et al. (2009): Gesprächsanalytisches Transkriptionssystem 2 (GAT 2). In:Gesprächsforschung 10, S. 353–402.