
Corpus of Turkish Youth Language (CoTY)
As an under-researched topic of investigation of an under-represented language, the defining linguistic characteristics of Turkish youth interaction have been invisible within both Turkish linguistics and cross-linguistic studies so far. To fill this gap, Dr. Esranur Efeoğlu-Özcan from the Middle East Technical University (METU) in Ankara compiled the first corpus of youth language for Turkish.
Efeoglu-Ozcan, E. (2022). The corpus of Turkish Youth Language (CoTY): The compilation and interactional dynamics of a spoken corpus. Dissertation. Available online at https://www.esraefeogluozcan.com/wp-content/uploads/2022/10/Efeoglu-Ozcan_Dissertation2022v2-1.pdf
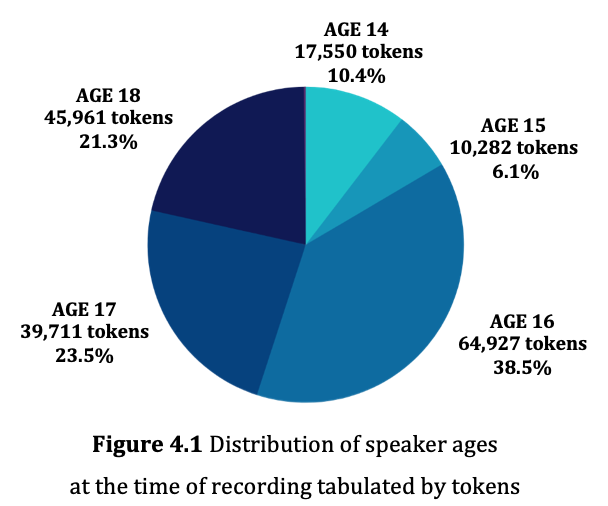
The Corpus of Turkish Youth Language (CoTY) is a specialized spoken corpus of 168,748 tokens constructed using EXMARaLDA. The CoTY has a single domain of informal conversation exclusively among friends between the ages of 14-18 from various socio-economic backgrounds in Turkey. The data is naturally occurring and spontaneous interactional data in Turkish along with occasional code-switches to English, as well as some words or expressions from French, Russian and Japanese. The CoTY is designed to encompass various modes and mediums of youth interaction and expand over the years, yet Dr. Efeoğlu-Özcan’s dissertation study specifically focuses on spoken data. The current version of the corpus has 123 unique speakers (62 female and 61 male) and consists of 49 conversations which correspond to 26 hours 11 minutes of interaction.
In addition to providing baseline data for further studies on contemporary spoken Turkish and cross-linguistic youth language studies, an additional overarching purpose of the corpus is to promote open science practices in linguistics by illustrating the affordances of corpus tools in terms of sustaining reproducibility, consistency, and transparency of language research.